type
Post
status
Published
date
Feb 12, 2025
slug
summary
tags
开发
思考
工具
category
技术分享
icon
password
1、写在开头DeepSeek典型模型的发展历程DeepSeek-V3的综合能力DeepSeek基础设施情况(估计可用超过 6 万张高端 GPU)2、DeepSeek模型2.1、强化学习驱动的推理能力突破2.2 Janus → Janus-Pro2.3 DeepSeek模型参数3、DeepSeek的创新之处3.1 DeepSeek-R1蒸馏3.2 MLA多层注意力架构3.3、FP8混合精度训练框架3.4、DualPipe 跨节点通信3.5、无辅助损失的负载均衡策略3.6、跨节点全对全通信内核3.7、MTP(多令牌预测)技术3.8、数据精筛4、DeepSeek可以做什么?4.1 用途4.2 分类5、演示5.1 在线使用5.2 本地运行5.2.1 DeepSeek-R15.2.2 DeepSeek-Janus-Pro6、参考文档
1、写在开头
- DeepSeek是私募量化巨头幻方量化旗下的一家大模型企业,成立于2023年5月份。专注通用人工智能(AGI)的中国科技公司,主攻大模型研发与应用。
- 2024年12月,开源DeepSeek V3模型,因为其良好的性能、超低的成本和友好的开源协议引起了广泛的关注。
- 2025年1月20日,开源DeepSeek R1推理大模型,其性能接近o1模型,且完全开源,调用成本降低了90-95%。
- ……
DeepSeek典型模型的发展历程
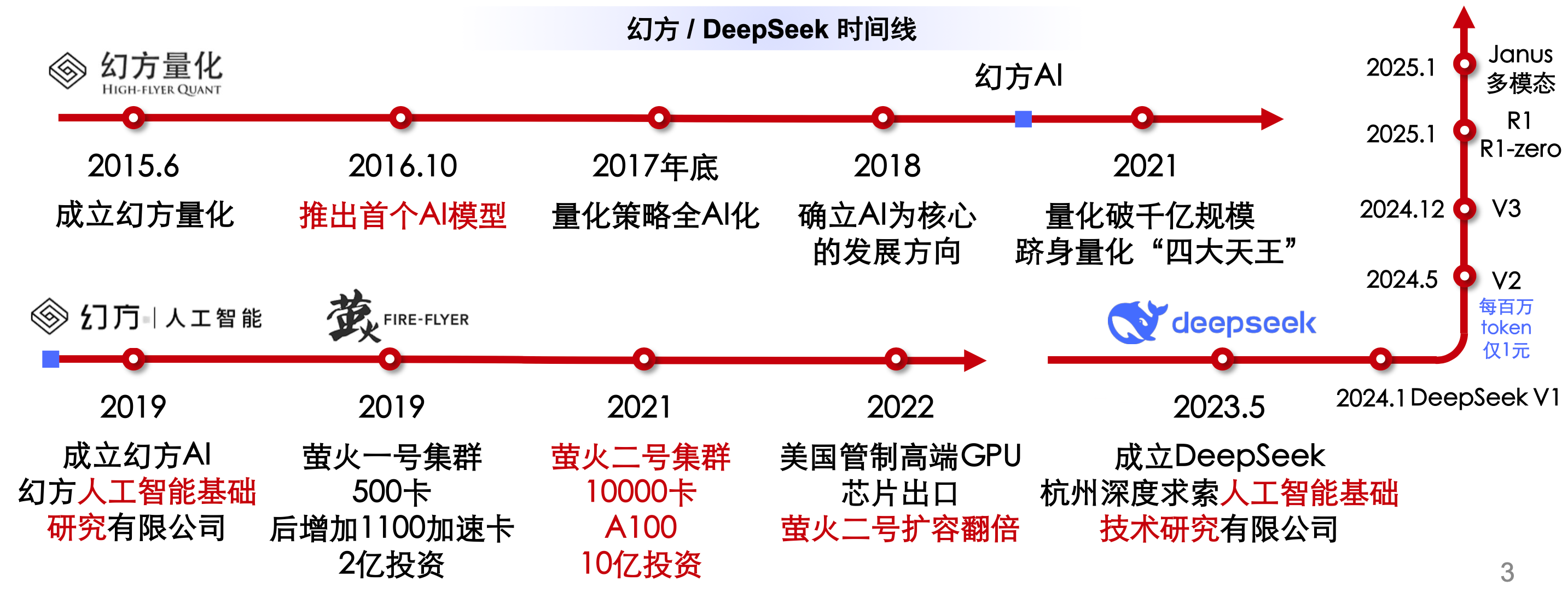

DeepSeek的每一次演进都围绕着效率、性能和实用性展开,展现了其在 AI 领域的持续创新和技术领先地位,DeepSeek 系列模型的架构演进可以概括为以下几个阶段:
- 基础架构:从 Transformer 架构出发,优化注意力机制和训练效率(DeepSeek LLM)。
- 专家混合模型:引入MoE架构,提升模型的专业化能力和效率(DeepSeekMoE)。
- 高效推理:通过MLA和多令牌预测(MTP)等技术,优化推理效率和训练成本(DeepSeek-V2、DeepSeek-V3)。
- 推理能力强化:利用强化学习和蒸馏技术,显著提升模型的推理能力和普及性(DeepSeek-R1 及蒸馏模型)。
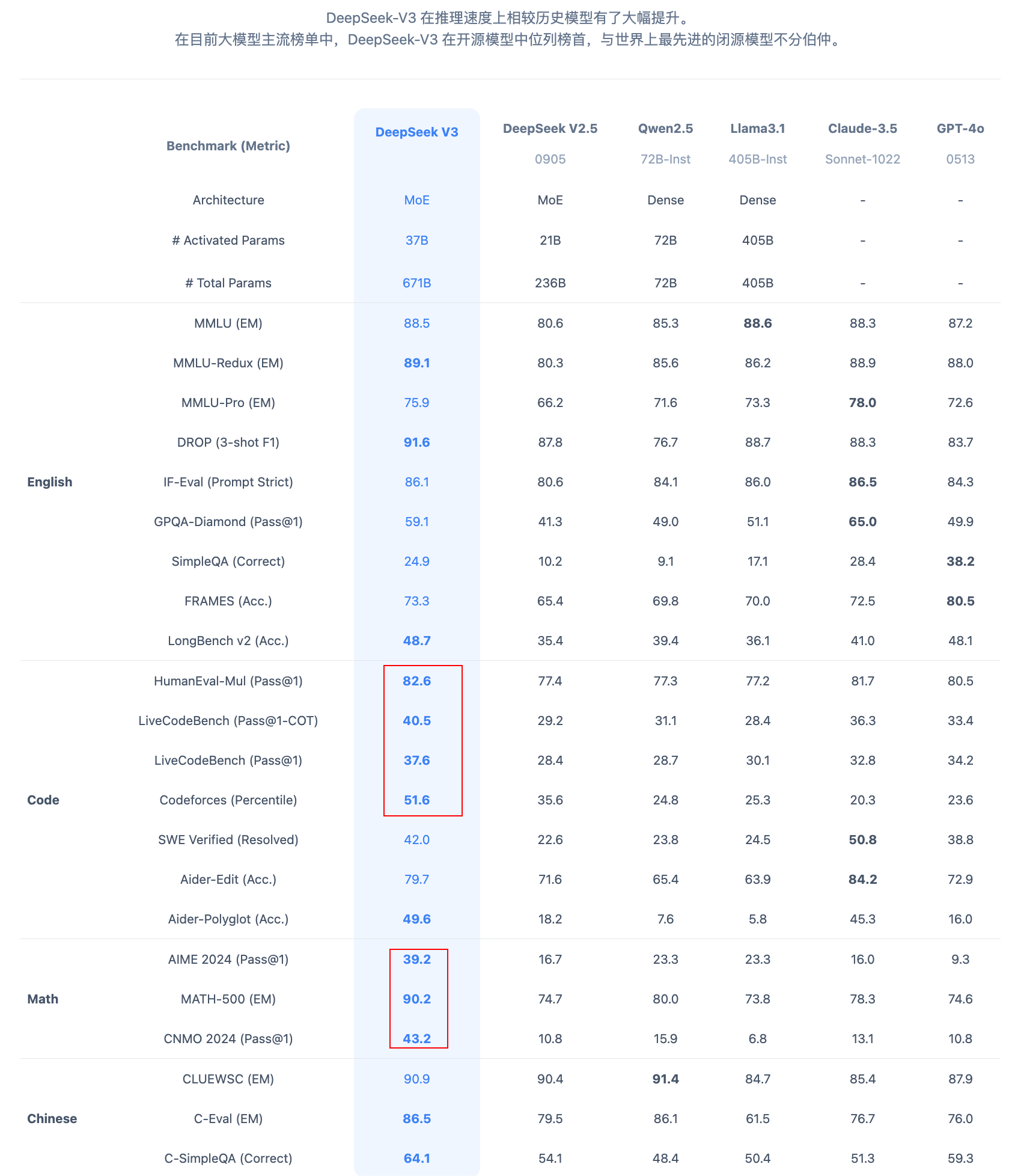
DeepSeek-V3的综合能力
DeepSeek-V3 在推理速度上相较历史模型有了大幅提升。
在目前大模型主流榜单中,DeepSeek-V3 在开源模型中位列榜首,与世界上最先进的闭源模型不分伯仲。
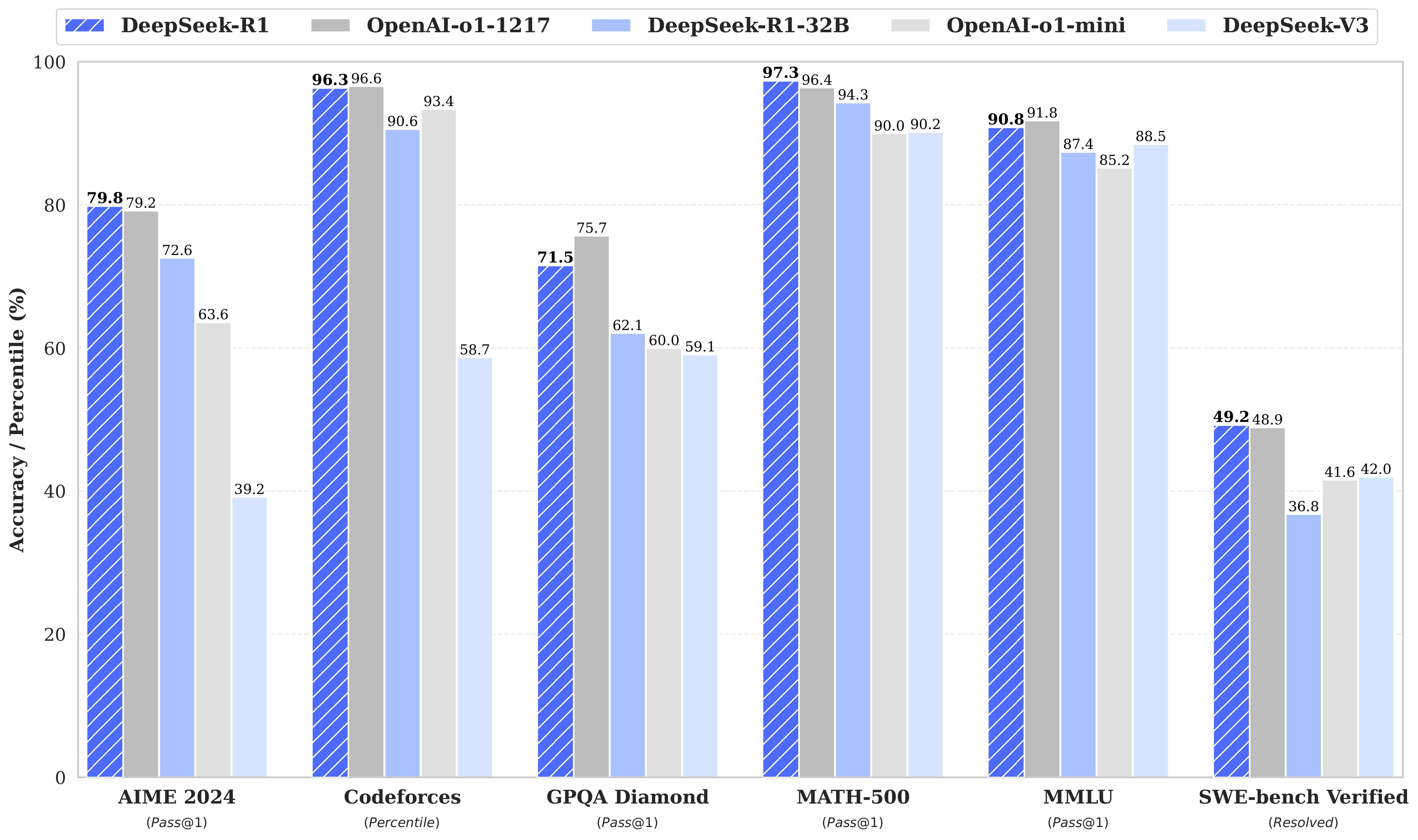
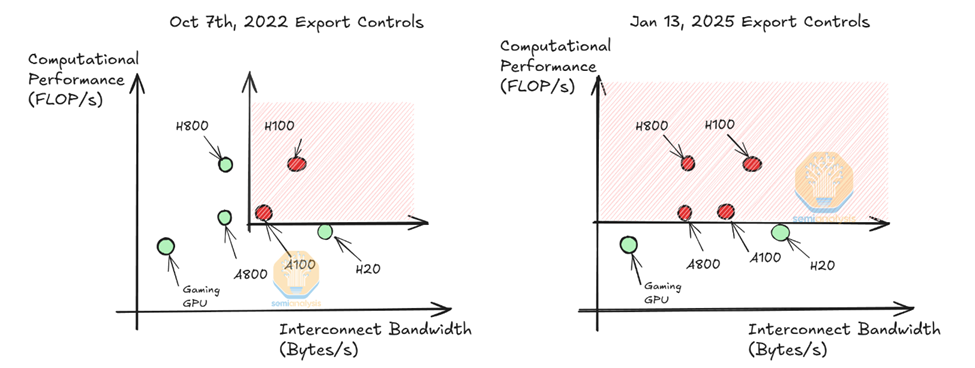
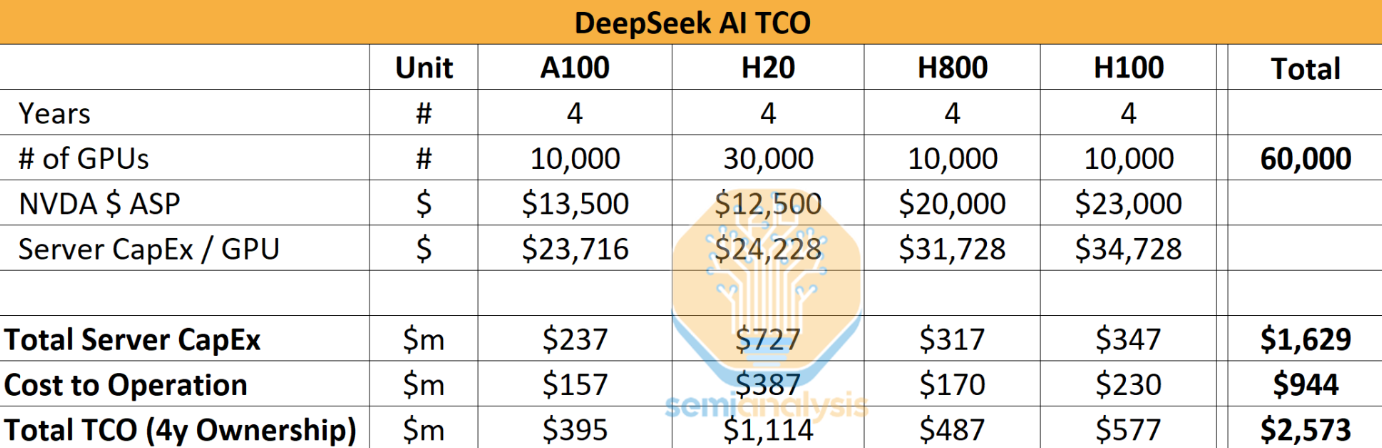
DeepSeek基础设施情况(估计可用超过 6 万张高端 GPU)
- DeepSeek-V3 布计算集群:2048 个 H800 GPU,节点内 NVLink 和 NVSwitch (160 GB/s),节点间 IB 网络 (50 GB/s)
- 据美方估计:幻方量化 和 深度求索 公司共享 10,000 A100 GPU (2021年之前购入),以及超过 50,000 张 Hopper 架构 GPU (10,000 张 H100 + 10,000 张 H800 + 超过 30,000 张 H20)。
- 模型实验角度预估:MTP多种深度及模型结构设计、MLA 超参实验及算法验证、MOE 共享层实等同时跑10个实验,每个实验需要2000张,至少要20000张。
- 估计采购服务器花费 16 亿美元,4 年运营成本约 9 亿美元,总计约 25 亿美元 (181亿人民币)
2、DeepSeek模型
2.1、强化学习驱动的推理能力突破
之前已发布的大模型训练方案都采用了 SFT+RL 的方式,即首先需要大量的 SFT 数据进行指令微调,再通过强化学习优化模型。而 DeepSeek 发现即使不使用 SFT,也可以通过大规模强化学习显著提高推理能力。此外,通过包含少量冷启动数据进行 SFT 就可以进一步提高性能。
2024 年 12 月 26 日, DeepSeek-V3 通用模型开源,其总参数量 671B,生成 token 时的激活参数为 37B。 R1-ZERO 是在 V3 的基础上进行优化的,仅使用了 RL,无 SFT。R1 在 ZERO 的基础上先进行冷启动,再进行 RL,最后 SFT。
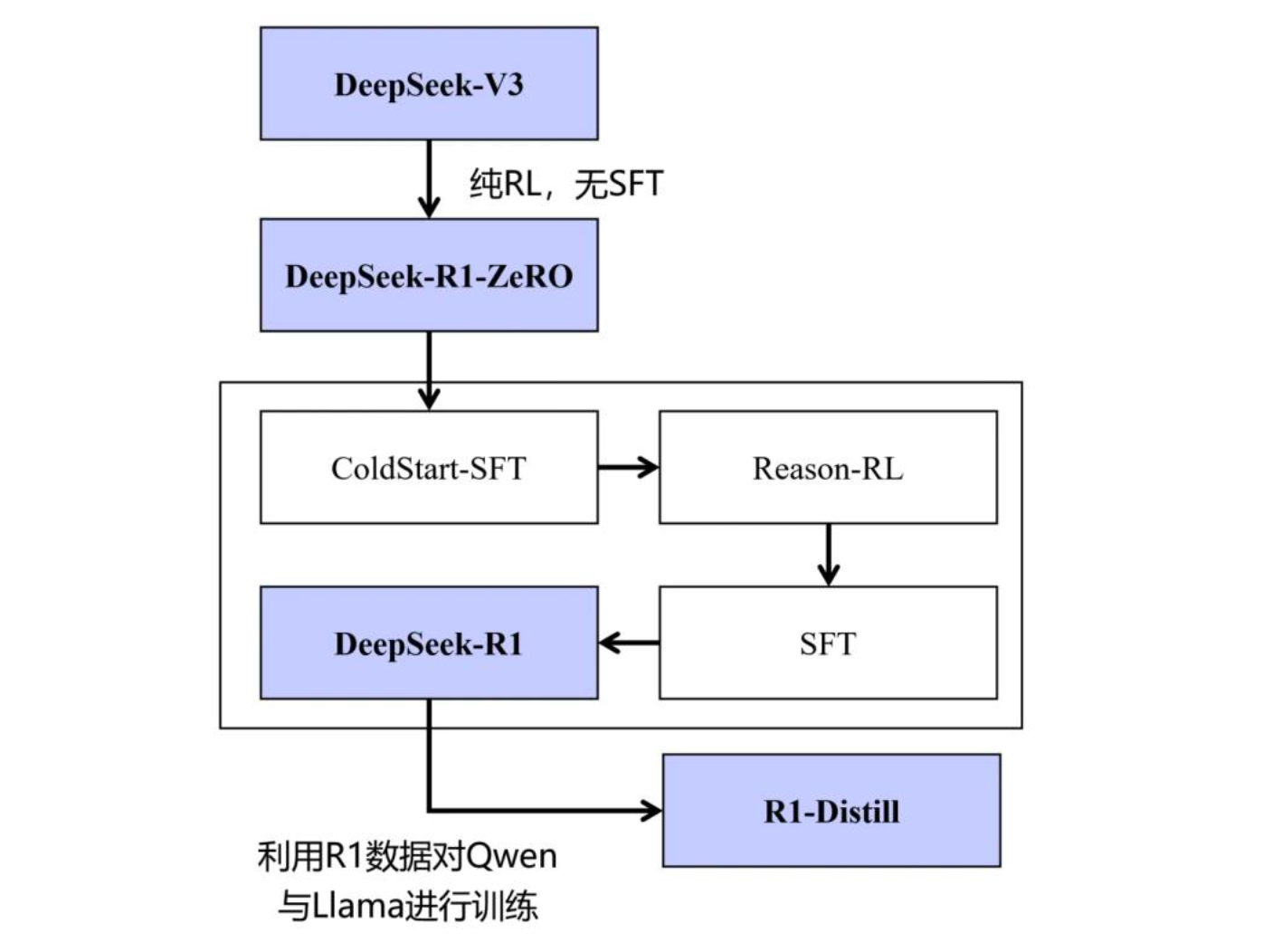
在 DeepSeek r1 的论文里,提到了 2 个模型,分别是 DeepSeek-R1-Zero 和 DeepSeek-R1:
- DeepSeek-R1-Zero:不用任何 SFT,仅使用 RL + 规则 RM,就能激发模型产出带反思的 Long CoT,取得不错的效果。
- DeepSeek-R1:加入少量(几千条)CoT 数据进行 SFT 作为冷启动,然后再进行RL,可以取得更优的性能,同时回答更符合人类偏好。
DeepSeek-R1-Zero
强化学习部分依然使用 DeepSeek 独家研发的 GRPO 框架。Reward Model 有所改变,没有训练常规的稠密奖励模型,而是采用了两种奖励方式结合:
- 准确性奖励:对于数学问题,直接匹配标准答案;对于代码问题,基于编译执行然后验证结果。
- 格式奖励:看 CoT 过程是否以标准<think> </think>包裹。之前用标签包裹每一段内容,是优化 prompt 的常用方法,这次 DeepSeek 把写 prompt 的方法融入到了 CoT训练数据中。简单暴力的规则,效果却出奇地好。但是 DeepSeek 的研发人员们发现 DeepSeek-R1-Zero 生成的答案可读性相对差、存在混合语言输出的问题。
DeepSeek-R1
为了解决 DeepSeek-R1-Zero 输出质量差的问题,就在此基础上进行了 SFT 和 RL,于是 DeepSeek-R1 就诞生了。DeepSeek-R1 采用如下 3 个阶段,又把能力进一步加强:
第一:CoT 数据冷启动
DeepSeek 收集到了少量(几千条)高质量的 CoT 数据,使用 few-shot 直接提示DeepSeek-R1-Zero 通过反思和验证生成详细答案,然后通过人工标注处理来细化结果。采用 CoT 数据,使用 SFT 方法进行冷启动,可以显著增强模型输出的可读,通过实验证明,也能进一步提升推理能力。
第二:全场景的强化学习
为了进一步使模型与人类偏好对齐,DeepSeek 实施了第二阶段的强化学习。对于推理数据,使用了 DeepSeek-R1-Zero 中概述的方法,该方法利用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程;对于通用数据,采用了奖励模型来捕捉复杂和细致场景中人类的偏好,基于DeepSeek-V3 的流程,并采用相似的偏好对和训练提示词分布。
第三:拒绝采样和监督微调
与最初主要关注推理的冷启动数据不同,此阶段构建推理数据和非推理数据,纳入了来自其他领域的数据来对模型进行 SFT,以提高模型的通用能力。
1.推理数据:采用拒绝采样的方式从前一阶段得到的模型生成推理过程。前一阶段只包括了基于规则的奖励数据,在此阶段,研发者额外扩充了数据集,其中一些数据通过将真实答案和模型预测输入到DeepSeek-V3 中进行判断,从而使用生成式奖励模型。同时,由于模型输出有时混乱且难以阅读,所以过滤掉了包含混合语言、长段落、代码块的 CoT 数据。对于每个提示词,DeepSeek 采样多个响应,并仅保留正确的响应,总共收集了大约 60 万个与推理相关的训练样本。
2.非推理数据:对于常规非推理数据,例如写作、翻译等,使用 DeepSeek-V3 的 SFT数据;对于某些非推理任务,会调用 DeepSeek-V3,通过提示词生成潜在的思维链,然后再回答问题;对于更简单的查询,例如“你好”,则不会在响应中提供思维链 CoT,而是直接回答。最终总共收集了大约 20 万个与推理无关的训练样本这一阶段总共生成了 80w 样本,用 DeepSeek-V3-Base 进行了 2 个 epoch 的 SFT,最后得到 R1 模型。
2.2 Janus → Janus-Pro
随着人工智能技术的快速发展,尤其是在多模态(即同时处理多种数据类型,比如图像和文本)领域,研究人员已经取得了不少进展。现有的很多模型,如 Chameleon,都尝试用同一个视觉编码器来处理理解和生成任务。例如,这些模型可以一方面理解图像的内容,另一方面生成符合图像的描述。然而,这种方法并不总是理想的。
理解和生成这两类任务需要处理的信息粒度不同,也就是说,模型在面对这两类任务时需要“看”图像的方式不同。如果用同一个视觉编码器去完成两种任务,很容易出现“力不从心”的情况。理解任务往往需要更细腻的视觉信息,而生成任务可能更注重大局和风格。因此,现有的统一模型通常在多模态理解任务上表现不佳,导致性能不够理想。
针对这个问题,DeepSeek 提出了 Janus 框架。Janus 的创新点在于,它解耦了视觉编码器,用两个不同的路径分别处理理解任务和生成任务。简单来说,Janus 不再用一个视觉编码器去同时处理两类任务,而是根据任务的不同需求,使用两个独立的编码器。这两个路径仍然通过一个统一的 Transformer 架构进行管理和协调。
Janus-Pro 是 DeepSeek 最新开源的多模态模型,是一种新颖的自回归框架,统一了多模态理解和生成。通过将视觉编码解耦为独立的路径,同时仍然使用单一的、统一的变压器架构进行处理,该框架解决了先前方法的局限性。这种解耦不仅缓解了视觉编码器在理解和生成中的角色冲突,还增强了框架的灵活性。
Janus-Pro 超过了以前的统一模型,并且匹配或超过了特定任务模型的性能,它的的简洁性、高灵活性和有效性使其成为下一代统一多模态模型的强大候选者。Janus-Pro 基于 DeepSeek-LLM-1.5b-base / DeepSeek-LLM-7b-base 构建。janus Pro 7B 在 2025 年 01 月 27 日发布,只用 14 天 256 张 A100 配置训练,生成理解图像超越此前最佳水平。
2.3 DeepSeek模型参数
DeepSeek 发布的首个大模型,包含 671 亿参数,在 2 万亿 token 的数据集上训练而成,涵盖中英文。其原理基于 Transformer 架构,通过对大规模文本数据的学习,模型能够理解和生成自然语言。在训练过程中,采用了优化的算法,使得模型在语言理解和生成任务上表现出色。
MOE模型 | 模型大小 | 共享专家 | 激活专家/总专家 | 激活比 |
Deepseek LLM | 7B/67B | 稠密模型 | ㅤ | ㅤ |
Deepseek MOE | 145B | 4 | 12/128 | 22/145=15.1% |
Deepseek V2 | 236B | 2 | 6/160 | 21/235=8.9% |
Deepseek V3 | 671B | 1 | 8/256 | 37/671=5.5% |
Deepseek R1 | 671B | 1 | 8/256 | 37/671=5.5% |
学生模型
Model | Base Model |
DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B |
DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B |
DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B |
DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B |
DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B |
DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-instruct |
3、DeepSeek的创新之处
从 DeepSeek-V2 到如今的 DeepSeek-V3,DeepSeek 公司在不断探索和优化模型架构、训练方法和基础设施,力求在性能和成本之间找到最佳平衡。 DeepSeek-V3 的出现,正是这一努力的最新成果,它不仅在多个基准测试中超越了其他开源模型,甚至在某些方面与领先的闭源模型相媲美。
3.1 DeepSeek-R1蒸馏
模型蒸馏(model Distillation)是一种模型压缩和知识迁移的技术,旨在将一个大型、复杂且性能优异的教师模型中的知识传递给一个较小、计算效率更高的学生模型。通过蒸馏,学生模型可以在保留教师模型大部分性能的同时,显著减少计算成本和模型参数规模。
由于 DeepSeek r1 参数量达到千亿级别,仅推理资源就需要 32 张 A100,为了解决资源有限场景下又能保留大部分性能的问题,DeepSeek 基于蒸馏技术和 QWen、Llama 基模蒸馏出不同版本的 DeepSeek R1 蒸馏模型,可以用一张趣图理解:

蒸馏过程中,使用 DeepSeek-R1 精选的 80 万个样本对开源模型(如 Qwen 和 Llama)进行了微调,直接蒸馏的方法显著增强了较小模型的推理能力。
3.2 MLA多层注意力架构
DeepSeek-V3 采用了多头潜在注意力(MLA)和 DeepSeekMoE 两大核心技术。MLA 通过低秩联合压缩注意力键和值,显著减少了推理期间的键值(KV)缓存,同时保持了与标准多头注意力(MHA)相当的性能。DeepSeekMoE 通过引入细粒度专家和共享专家机制,实现了更高效的训练和推理。与传统的 MoE 架构相比, DeepSeekMoE 不仅提高了计算效率,还通过无辅助损失的负载平衡策略,避免了因负载不均导致的性能下降。
3.3、FP8混合精度训练框架
在训练精度方面,DeepSeek-V3 首次在大规模模型上验证了 FP8 混合精度训练框架的有效性。 FP8 格式以其较小的存储空间和计算开销,为高效训练提供了新的可能。然而,低精度训练也面临着激活、权重和梯度中异常值带来的挑战。DeepSeek 团队通过引入细粒度量化策略和高精度累积技术,成功克服了这些困难,实现了 FP8 训练的稳定性和高效性。这一创新不仅降低了训练成本,还为未来硬件的发展提供了新的方向。
3.4、DualPipe 跨节点通信
为了应对 DeepSeek-MOE 中跨节点专家并行带来的高通信开销,DeepSeek-V3设计了 DualPipe 算法,实现了计算和通信的高效重叠。通过将每个训练块细分为多个部分,并在前向和后向传播过程中交替执行计算和通信任务,DualPipe 算法显著减少了管道气泡,提高了训练过程中的计算利用率。这一策略不仅解决了大规模分布式训练中的通信瓶颈问题,还为模型的进一步扩展提供了可能。
3.5、无辅助损失的负载均衡策略
负载均衡一直是 MoE 模型训练中的一个关键挑战。传统方法通常依赖辅助损失来确保负载均衡,但这往往会牺牲模型性能。DeepSeek-V3 首创了一种无辅助损失的负载平衡策略,通过动态调整专家的偏置项,实现了训练过程中的负载均衡,同时最大限度地减少了对模型性能的负面影响。这一策略不仅提高了训练效率,还为 MoE 模型的进一步发展提供了新的思路。
3.6、跨节点全对全通信内核
DeepSeek 还专门定制了高效的跨节点 all-all 通信内核(包括调度和组合)。具体来说:跨节点 GPU 通过 IB 完全互连,节点内通信通过 NVLink 处理,每个 Token 最多调度到 4 个节点从而减少 IB 通信量。同时使用 warp 专业化技术做调度和组合的优化。
3.7、MTP(多令牌预测)技术
MTP 技术是 2024 年 meta 4 月提出来的,但 DeepSeek 团队在工程应用上做的快,DeepSeek-V3 引入了 MTP 技术。与传统的单标记预测不同,MTP 能够预测每个位置的多个未来标记,从而增强了模型对长序列的建模能力。这一目标不仅提高了模型在基准测试中的表现,还为推理阶段的加速提供了可能。
3.8、数据精筛
DeepSeek LLM 使用了规模庞大的双语数据集进行预训练,数据集包含 2 万亿字符。这一数据量远超同期许多其他模型所使用的数据集规模。如此大规模的数据集为模型提供了丰富的语言模式和知识,使其能够更好地理解和生成多种语言的文本。双语数据集的设计也意味着 DeepSeek LLM 在处理多语言任务时具有天然的优势,能够更有效地捕捉不同语言之间的共性和差异,提升模型在跨语言任务中的表现。
4、DeepSeek可以做什么?
直接面向用户或者支持开发者,提供智能对话、文本生成、语义理解、计算推理、代码生成补全等应用场景,支持联网搜索与深度思考模式,同时支持文件上传,能够扫描读取各类文件及图片中的文字内容。
4.1 用途
文本生成
- 文本创作
- 摘要与改写
- 结构化生成
自然语言理解与分析
- 语义分析
- 文本分类
- 知识推理
编程与代码相关
- 代码生成
- 代码调试
- 技术文档处理
绘图
- 数据图表
- ..
其他
4.2 分类
推理模型
推理大模型: 推理大模型是指能够在传统的大语言模型基础上,强化推理、逻辑分析和决策能力的模型。它 们通常具备额外的技术,比如强化学习、神经符号推理、元学习等,来增强其推理和问题解决能力。
例如:DeepSeek-R1,GPT-o3在逻辑推理、数学推理和实时问题解决方面表现突出。
非推理大模型: 适用于大多数任务,非推理大模型一般侧重于语言生成、上下文理解和自然语言处理,而不强 调深度推理能力。此类模型通常通过对大量文本数据的训练,掌握语言规律并能够生成合适的内容,但缺乏像 推理模型那样复杂的推理和决策能力。
例如:GPT-3、GPT-4(OpenAI),BERT(Google),主要用于语言生成、语言理解、文本分类、翻译 等任务。
维度 | 推理模型 | 通用模型 |
优势领域 | 数学推导、逻辑分析、代码生成、复杂问题拆解 | 文本生成、创意写作、多轮对话、开放性问答 |
劣势领域 | 发散性任务(如诗歌创作 | 需要严格逻辑链的任务(如数学证明) |
性能本质 | 专精于逻辑密度高的任务 | 擅长多样性高的任务 |
强弱判断 | 并非全面更强,仅在其训练目标领域显著优于通用模型 | 通用场景更灵活,但专项任务需依赖提示语补偿能力 |
5、演示
5.1 在线使用
网页在线使用





API接入,IDEA使用CodeGPT接入
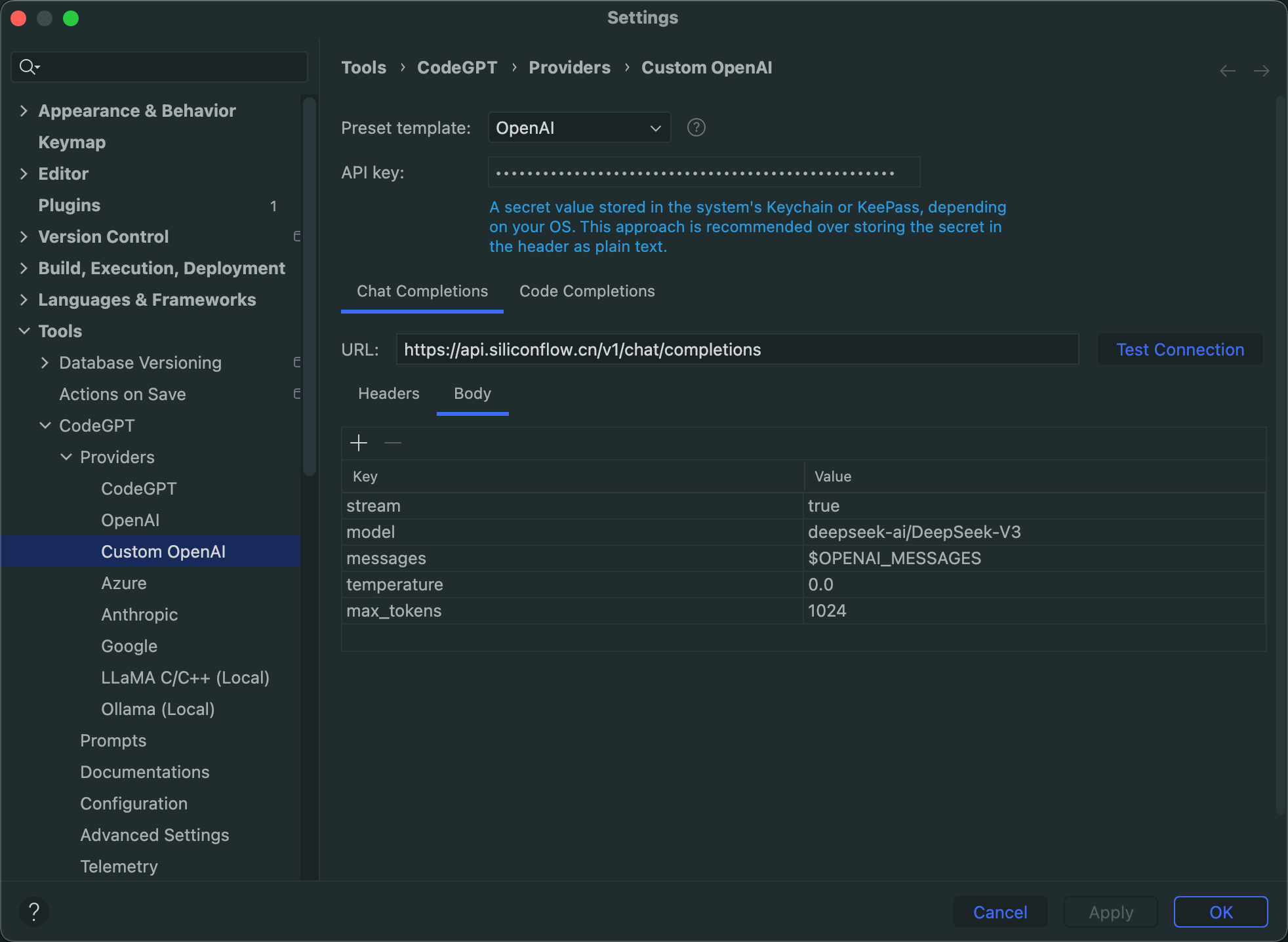
5.2 本地运行
5.2.1 DeepSeek-R1

ollama run deepseek-r1:1.5b ollama run deepseek-r1:7b
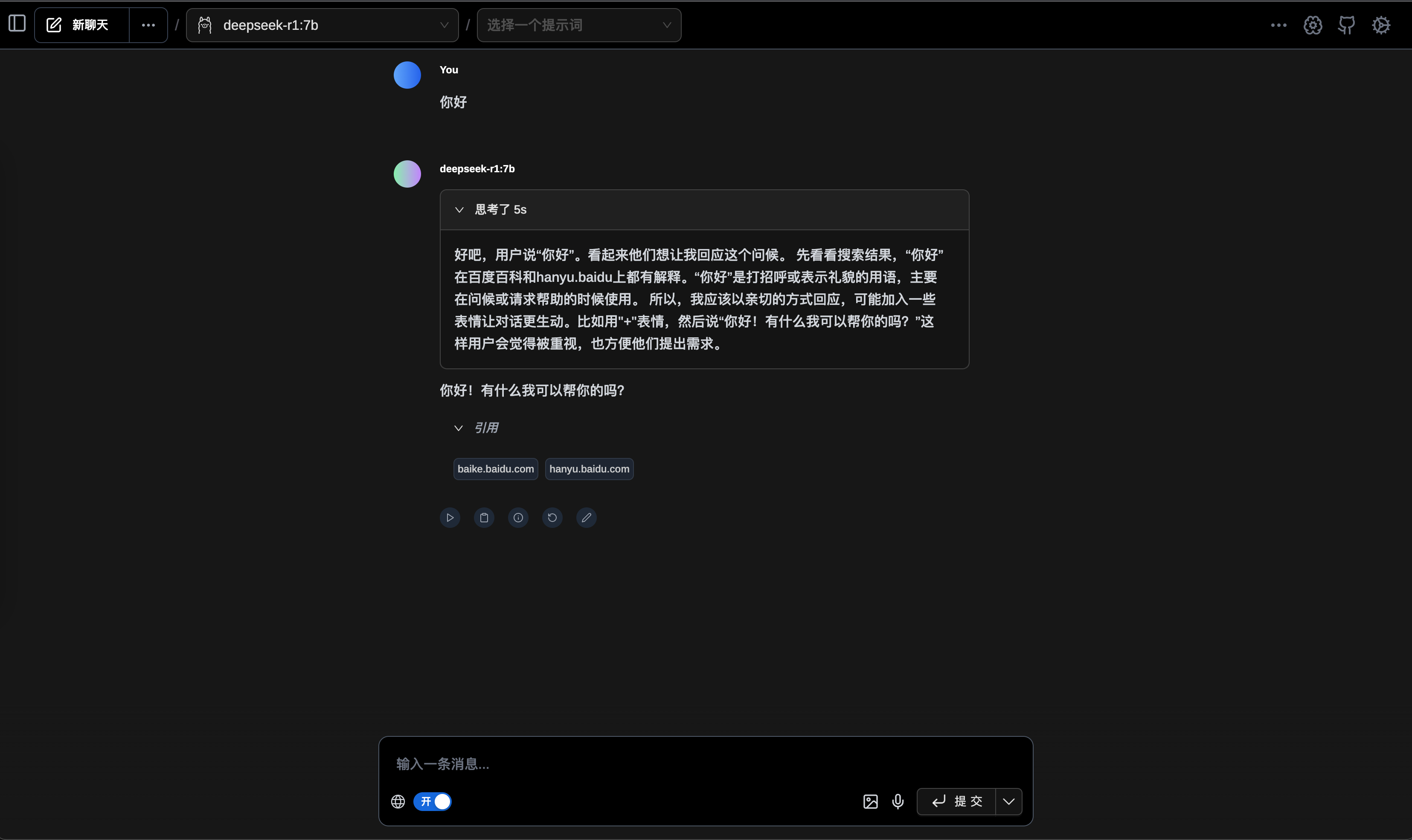
使用命令行执行

使用WebUI运行演示
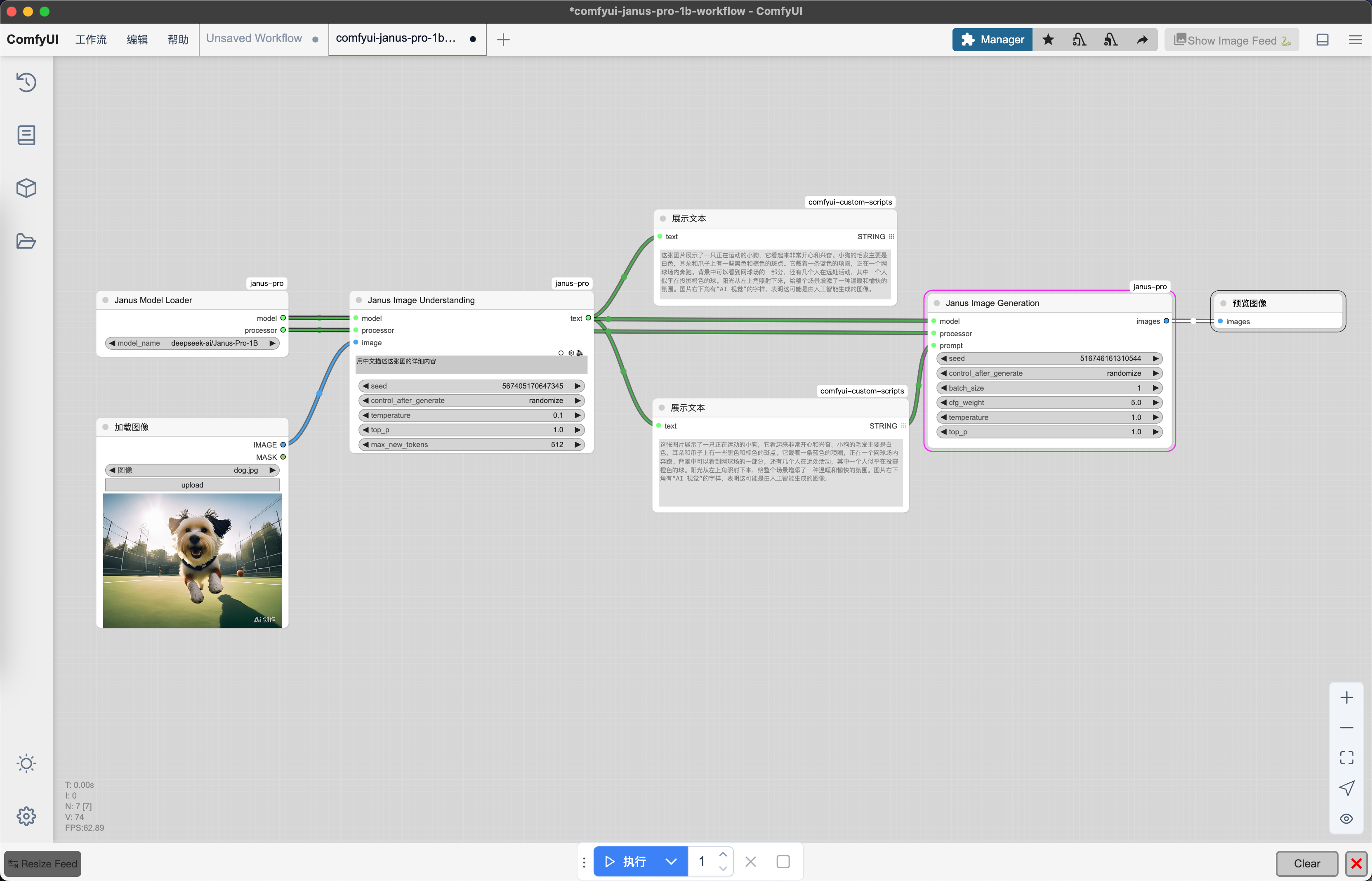
5.2.2 DeepSeek-Janus-Pro
Janus
deepseek-ai • Updated May 28, 2025


使用ComfyUI运行演示