type
Post
status
Published
date
Aug 4, 2025
slug
summary
tags
开发
工具
category
技术分享
icon
password
1、写在开头1.1 背景1.2 deepwiki是什么?1.3 官网使用案例1.4 官方私有使用2、DeepWiki-Open2.1 简介2.2 功能特点2.3 部署使用2.4 工作原理2.5 相关配置解释2.6 演示示例3、相关引用
1、写在开头
1.1 背景
DeepWiki 是由 Cognition AI(原 Devin 团队)开发的 AI 驱动工具,专注于为 GitHub 代码仓库生成交互式文档和可视化分析,帮助开发者快速理解复杂项目。
Devin AI 是由 Cognition Labs 开发的自主人工智能助手工具,标榜为 “AI 软件开发者”。曾号称全球首个全自动 AI 程序员,因执行成本高导致订阅价格也极高($500/月),后来就淡出人们视野了。目前更主流的开发形式是
IDE + MCP(如 Cursor、VSCode、Windsurf 等),半自动化的工具链调用让控制更精准,结果也变得更加可靠。阅读开源项目的一些痛点
GitHub 主流开源项目介绍以英文 README.md 为主,支持多语言介绍的并不多,对于非母语的人来说,存在一定阅读障碍
很多仓库可能连比较像样的 README 介绍都没,更别提专门的文档网站或 Blog 了。于开发者而言是灾难性的,需要自行查看源代码或在 issues 中搜寻一些描述
如果仓库文件超多,上百个文件,或大几十万行代码,想要通过阅读源码来建立项目宏观认知会变得特别难
在项目文档中不会有功能与源码之间的映射关系说明,但这又是借鉴参考项目时的一个重点需求
1.2 deepwiki是什么?
核心功能
自动化文档生成:通过分析代码结构、README 和配置文件,自动生成项目概述、技术栈、核心模块及依赖关系文档,减少逐行阅读代码的需求
交互式图表:提供架构图、类图、函数调用关系图等可视化工具,直观展示代码结构
对话式AI助手:支持开发者直接向代码库提问,获取源码解析、使用方法和架构设计等详细解答
实时更新与私有支持:可自动同步仓库更新,并为私有项目生成知识库(需注册 Devin.ai 账号)
使用方法
公共仓库:将GitHub链接中的
github.com替换为deepwiki.com(例如https://deepwiki.com/用户名/仓库名)即可访问专属Wiki页面私有仓库:需在 Devin.ai 注册账号并授权访问权限
适用场景
开源项目学习:快速掌握陌生仓库的架构和核心逻辑
团队协作:生成标准化文档,降低新成员学习成本
代码审计:通过依赖关系图定位潜在风险模块
特点与优势
完全免费:对开源项目无任何使用限制
低门槛:无需编程即可通过自然语言交互获取信息
大规模处理能力:支持超大型仓库分析,如 Linux 内核等复杂项目

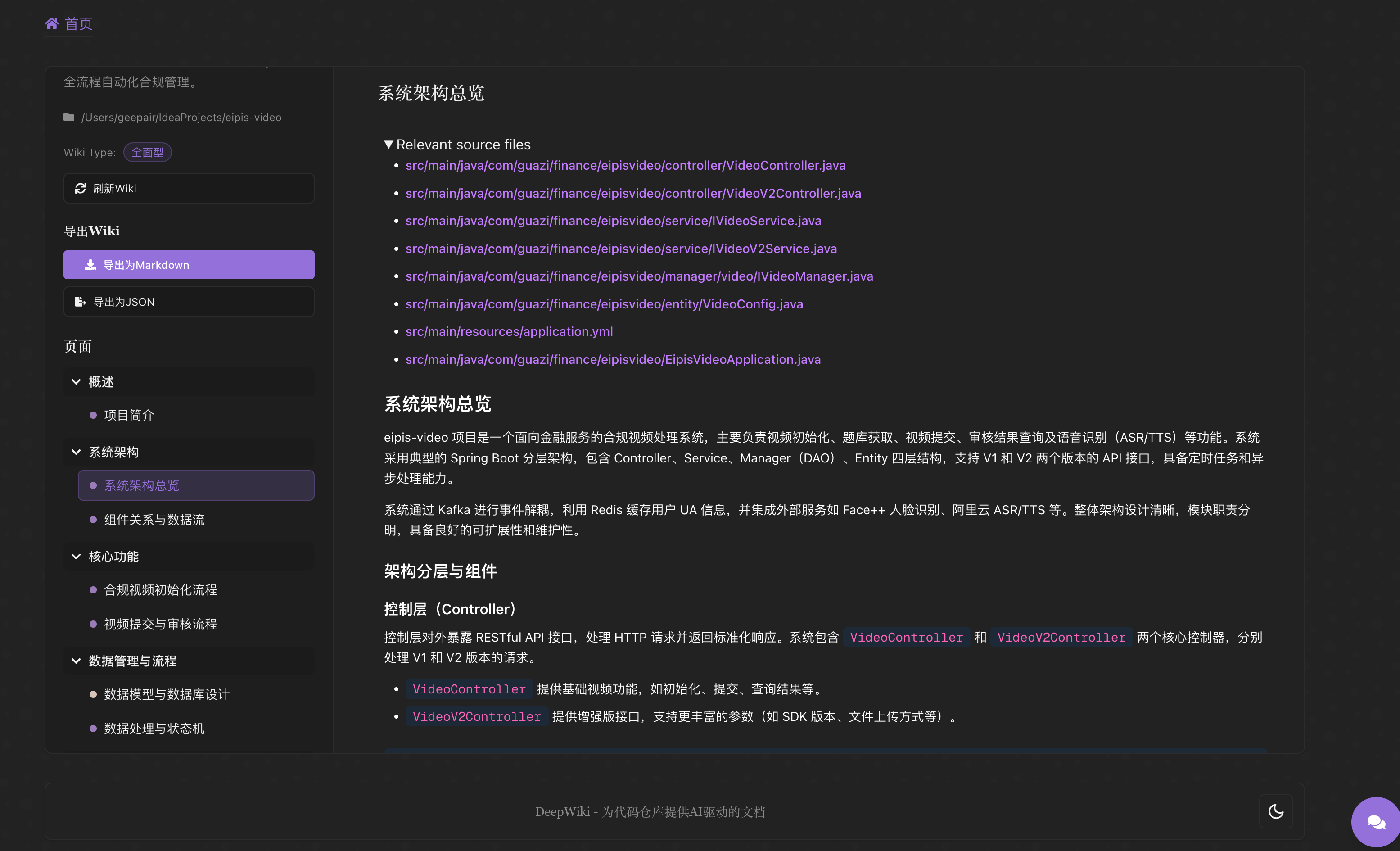
1.3 官网使用案例
VSCode示例 /microsoft/vscode
功能点:
- 生成综合的结构化的README文档内容,从系统设计来看,模型在局部理解代码(如函数、模块)方面表现非常出色,但真正的挑战在于理解整个代码库的全局结构。DeepWiki 针对这一难题,采用了分层方法:先将代码库划分为一套套高层次系统(high-level systems),再为每一个系统生成对应的 Wiki 页面,帮助用户在整体上把握项目架构
- 生成多维度系统架构图、ER图、时序图、流程图等
- 提供对话功能(交互式问答),直接对生成的Wiki发起提问,DeepWiki 会根据代码库内容智能回答
- 历史提交索引,通过分析哪些文件经常被一起修改,可以构建出文件之间的关联图(graph),从而揭示项目内部许多潜在且重要的结构模式。这一方法进一步增强了 DeepWiki 对代码库内部逻辑关系的理解与呈现,文档会根据代码库更新自动同步
- 显示相关资源文件关联,行号关联等
- …
项目文档结构
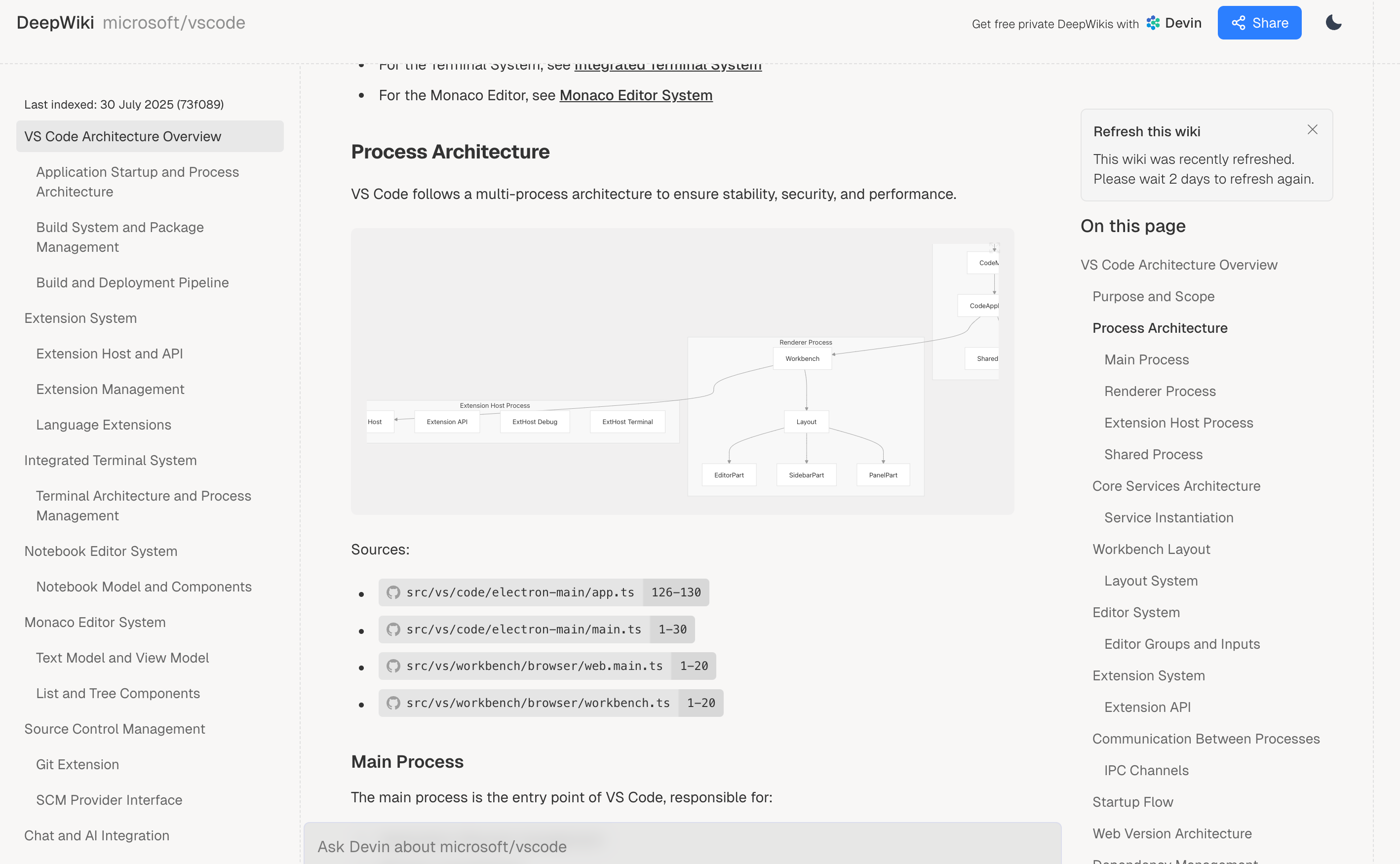
问答示例
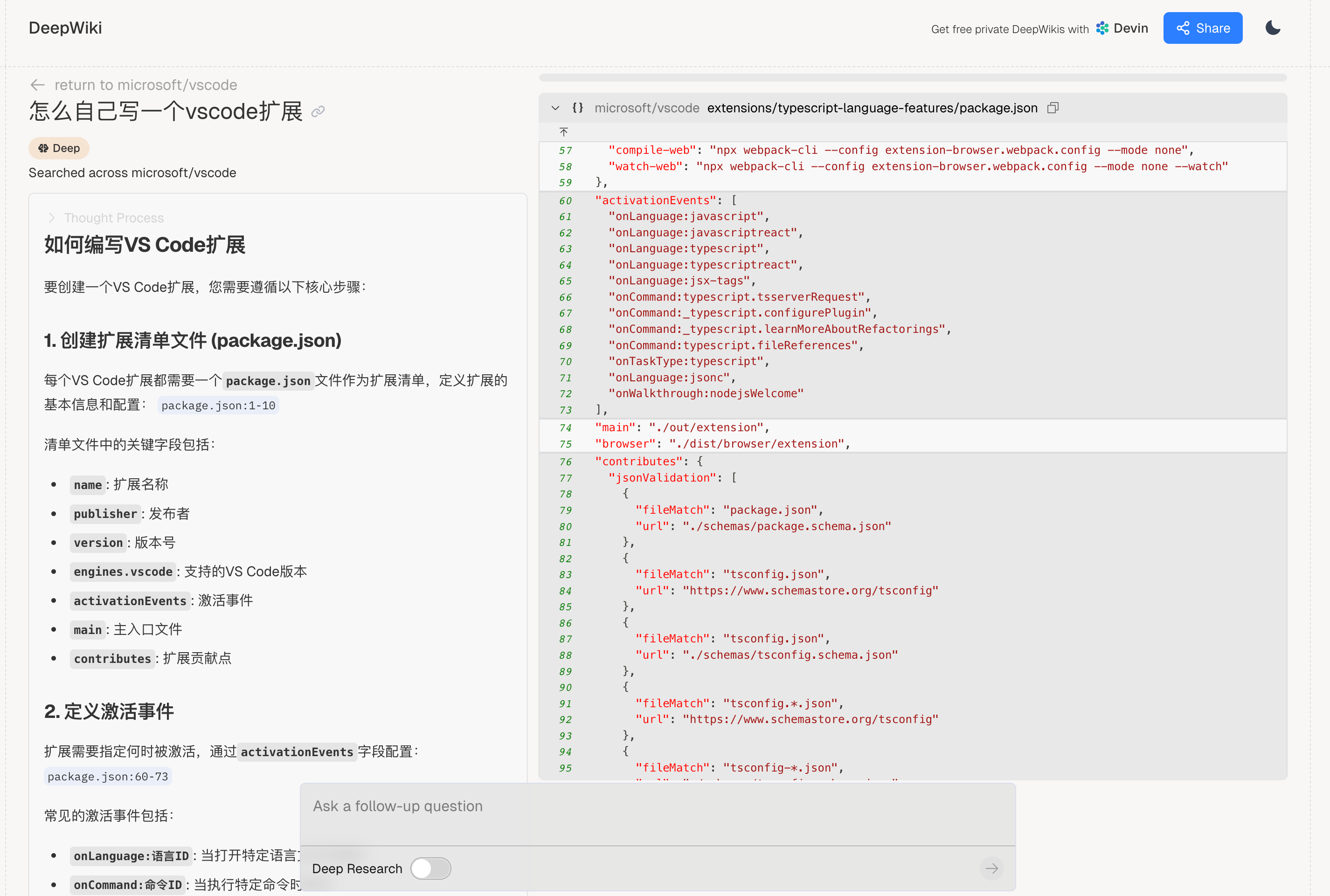
1.4 官方私有使用
Devin AI
导入自己的Git仓库
- 公有代码仓库
- 私有代码仓库
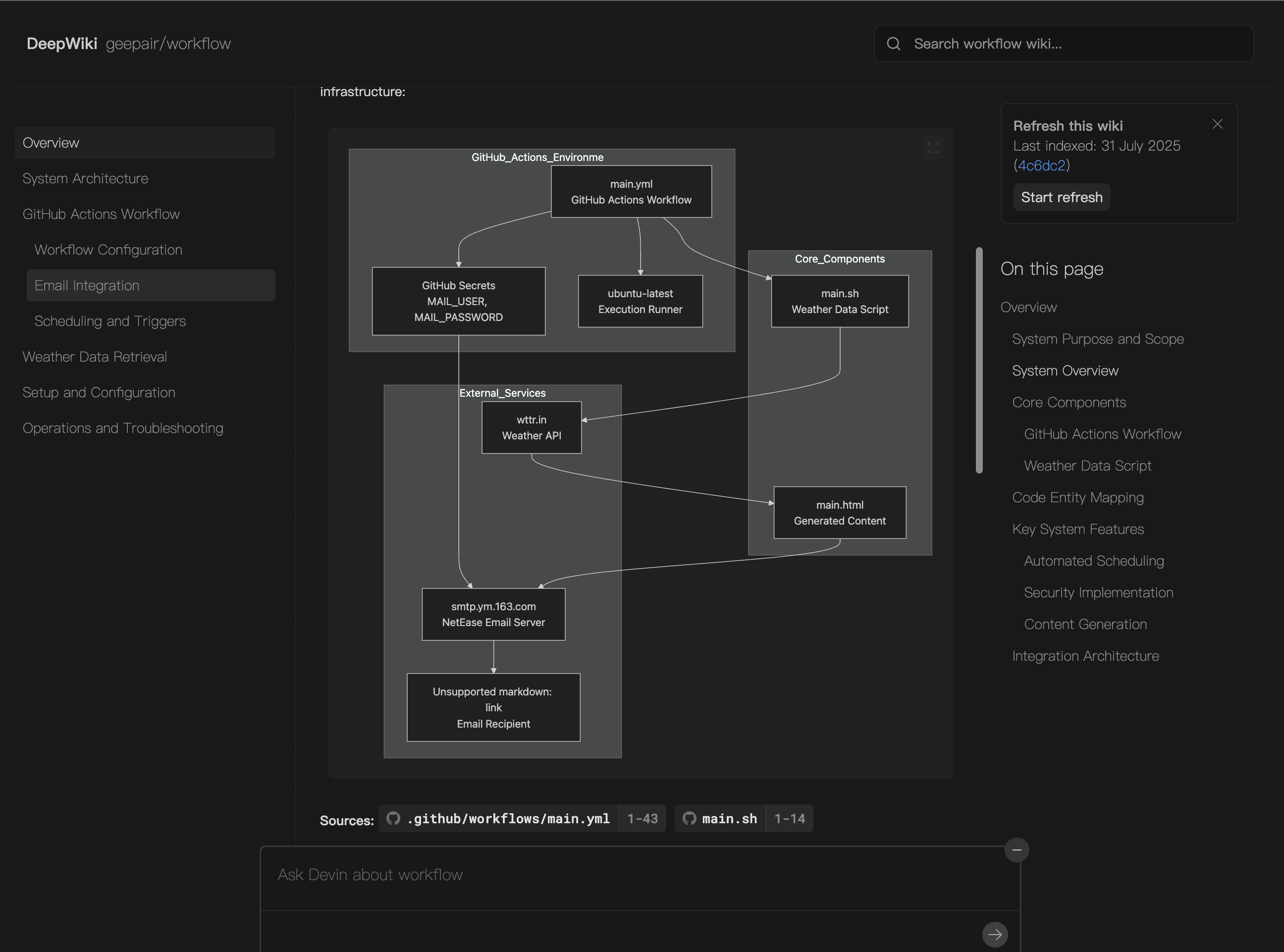
简单示例
workflow
geepair • Updated Aug 26, 2022
2、DeepWiki-Open
2.1 简介
deepwiki-open
AsyncFuncAI • Updated Sep 8, 2025
DeepWiki可以为任何GitHub、GitLab或BitBucket代码仓库自动创建美观、交互式的Wiki!只需输入仓库名称,DeepWiki将:
- 分析代码结构
- 生成全面的文档
- 创建可视化图表解释一切如何运作
- 将所有内容整理成易于导航的Wiki
2.2 功能特点
- 即时文档:几秒钟内将任何GitHub、GitLab或BitBucket仓库转换为Wiki
- 私有仓库支持:使用个人访问令牌安全访问私有仓库
- 智能分析:AI驱动的代码结构和关系理解
- 精美图表:自动生成Mermaid图表可视化架构和数据流
- 简易导航:简单、直观的界面探索Wiki
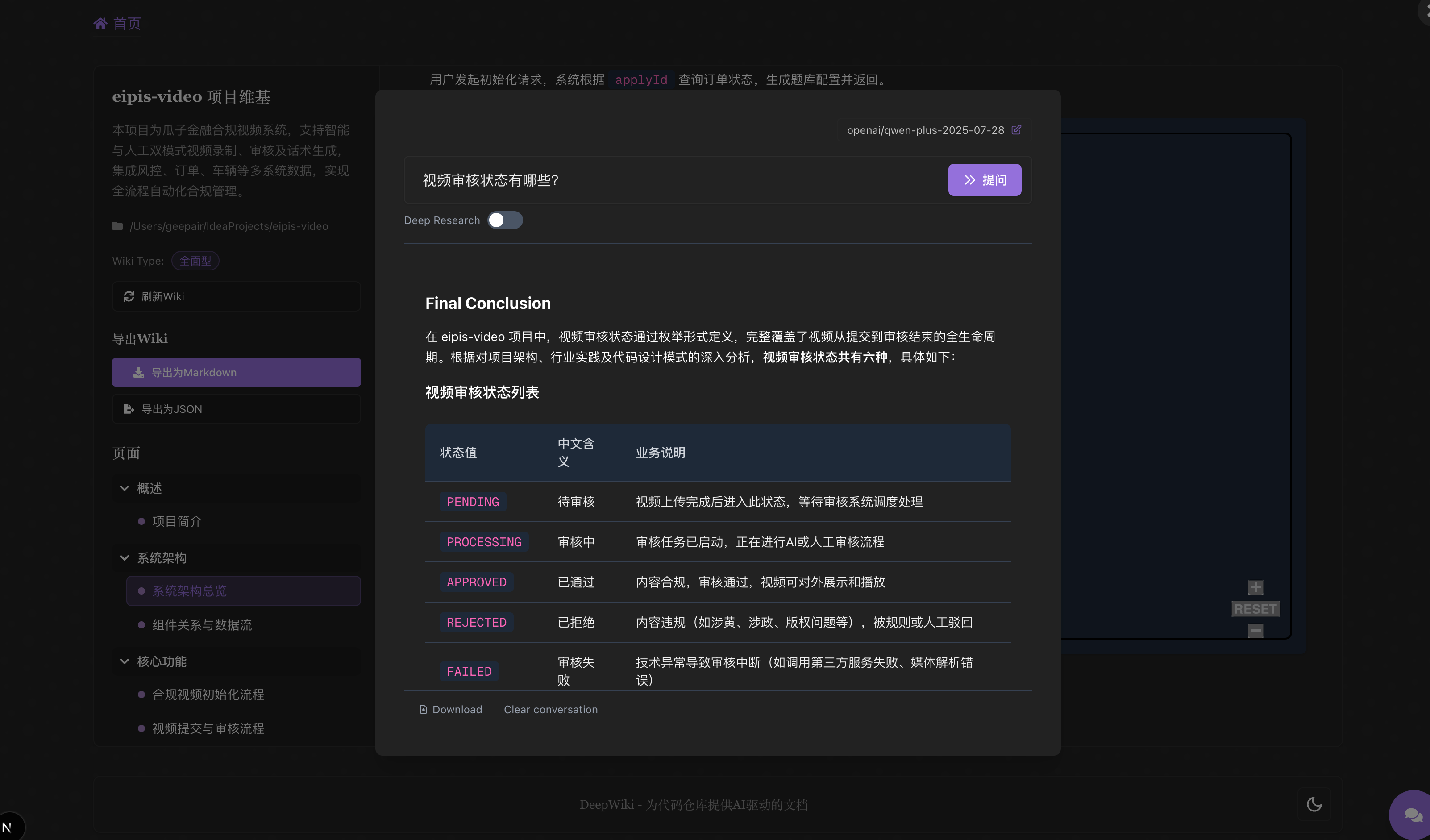
- 提问功能:使用RAG驱动的AI与您的仓库聊天,获取准确答案
- 深度研究:多轮研究过程,彻底调查复杂主题
- 多模型提供商:支持Google Gemini、OpenAI、OpenRouter和本地Ollama模型
2.3 部署使用
docker部署
# 克隆仓库 git clone https://github.com/AsyncFuncAI/deepwiki-open.git cd deepwiki-open # 创建包含API密钥的.env文件 echo "GOOGLE_API_KEY=your_google_api_key" > .env echo "OPENAI_API_KEY=your_openai_api_key" >> .env # 可选:如果您想使用OpenRouter模型,添加OpenRouter API密钥 echo "OPENROUTER_API_KEY=your_openrouter_api_key" >> .env # 使用Docker Compose运行 docker-compose up
(上述 Docker 命令以及
docker-compose.yml 配置会挂载您主机上的 ~/.adalflow 目录到容器内的 /root/.adalflow。此路径用于存储:- 克隆的仓库 (
~/.adalflow/repos/)
- 仓库的嵌入和索引 (
~/.adalflow/databases/)
- 缓存的已生成 Wiki 内容 (
~/.adalflow/wikicache/)
手动设置(推荐)
- 设置API密钥
GOOGLE_API_KEY=your_google_api_key OPENAI_API_KEY=your_openai_api_key # 可选:如果您想使用OpenRouter模型,添加此项 OPENROUTER_API_KEY=your_openrouter_api_key
- 启动后端
# 安装Python依赖 pip install -r api/requirements.txt # 启动API服务器 python -m api.main
# 安装Python依赖 uv venv --python 3.12 source .venv/bin/activate uv pip install -r api/requirements.txt # 启动API服务器 uv run -m api.main
- 启动前端
# 安装JavaScript依赖 npm install # 或 yarn install # 启动Web应用 npm run dev # 或 yarn dev
- 使用deepwiki
{ "message": "Welcome to Streaming API", "version": "1.0.0", "endpoints": { "Docs": [ "GET /docs/oauth2-redirect" ], "Lang": [ "GET /lang/config" ], "Auth": [ "GET /auth/status", "POST /auth/validate" ], "Models": [ "GET /models/config" ], "Export": [ "POST /export/wiki" ], "Local_repo": [ "GET /local_repo/structure" ], "Chat": [ "POST /chat/completions/stream" ], "Api": [ "DELETE /api/wiki_cache", "GET /api/processed_projects", "GET /api/wiki_cache", "POST /api/wiki_cache" ], "Health": [ "GET /health" ], "Root": [ "GET /" ] } }
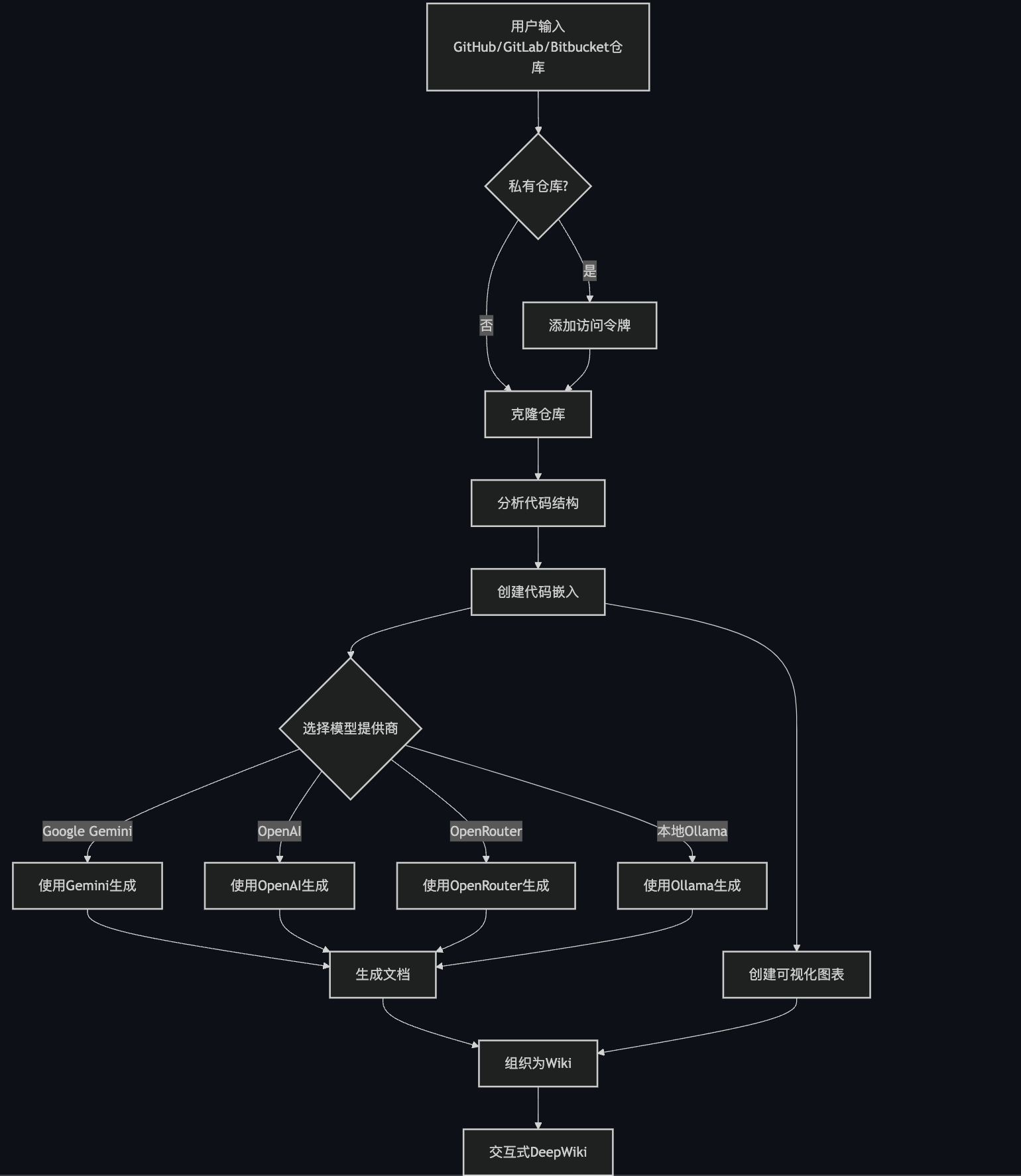
2.4 工作原理
DeepWiki使用AI来:
- 克隆并分析GitHub、GitLab或Bitbucket仓库(包括使用令牌认证的私有仓库)
- 创建代码嵌入用于智能检索
- 使用上下文感知AI生成文档(使用Google Gemini、OpenAI、OpenRouter或本地Ollama模型)
- 创建可视化图表解释代码关系
- 将所有内容组织成结构化Wiki
- 通过提问功能实现与仓库的智能问答
- 通过深度研究功能提供深入研究能力
流程图
项目结构
deepwiki/ ├── api/ # 后端API服务器 │ ├── main.py # API入口点 │ ├── api.py # FastAPI实现 │ ├── rag.py # 检索增强生成 │ ├── data_pipeline.py # 数据处理工具 │ └── requirements.txt # Python依赖 │ ├── src/ # 前端Next.js应用 │ ├── app/ # Next.js应用目录 │ │ └── page.tsx # 主应用页面 │ └── components/ # React组件 │ └── Mermaid.tsx # Mermaid图表渲染器 │ ├── public/ # 静态资源 ├── package.json # JavaScript依赖 └── .env # 环境变量(需要创建)
2.5 相关配置解释
配置文本嵌入模型
{ "embedder": { "client_class": "OpenAIClient", "initialize_kwargs": { "api_key": "${OPENAI_API_KEY}", "base_url": "${OPENAI_BASE_URL}" }, "batch_size": 10, "model_kwargs": { "model": "text-embedding-v4", "dimensions": 1024, "encoding_format": "float" } }, "retriever": { "top_k": 20 }, "text_splitter": { "split_by": "word", "chunk_size": 350, "chunk_overlap": 100 } }
配置对话模型
{ "default_provider": "openai", "providers": { "dashscope": { "default_model": "qwen-plus", "supportsCustomModel": true, "models": { "qwen-plus": { "temperature": 0.7, "top_p": 0.8 }, "qwen-turbo": { "temperature": 0.7, "top_p": 0.8 }, "deepseek-r1": { "temperature": 0.7, "top_p": 0.8 } } }, "google": { "default_model": "gemini-2.0-flash", "supportsCustomModel": true, "models": { "gemini-2.0-flash": { "temperature": 0.7, "top_p": 0.8, "top_k": 20 }, "gemini-2.5-flash-preview-05-20": { "temperature": 0.7, "top_p": 0.8, "top_k": 20 }, "gemini-2.5-pro-preview-03-25": { "temperature": 0.7, "top_p": 0.8, "top_k": 20 } } }, "openai": { "default_model": "gpt-4o", "supportsCustomModel": true, "models": { "gpt-4o": { "temperature": 0.7, "top_p": 0.8 }, "gpt-4.1": { "temperature": 0.7, "top_p": 0.8 }, "o1": { "temperature": 0.7, "top_p": 0.8 }, "o3": { "temperature": 1.0 }, "o4-mini": { "temperature": 0.7, "top_p": 0.8 }, "qwen-plus-2025-07-28": { "temperature": 0.7, "top_p": 0.8 } } } } }
前端相关配置
- dev跨域访问
- …
2.6 演示示例
配置好后启动前后端服务
导入后的项目列表
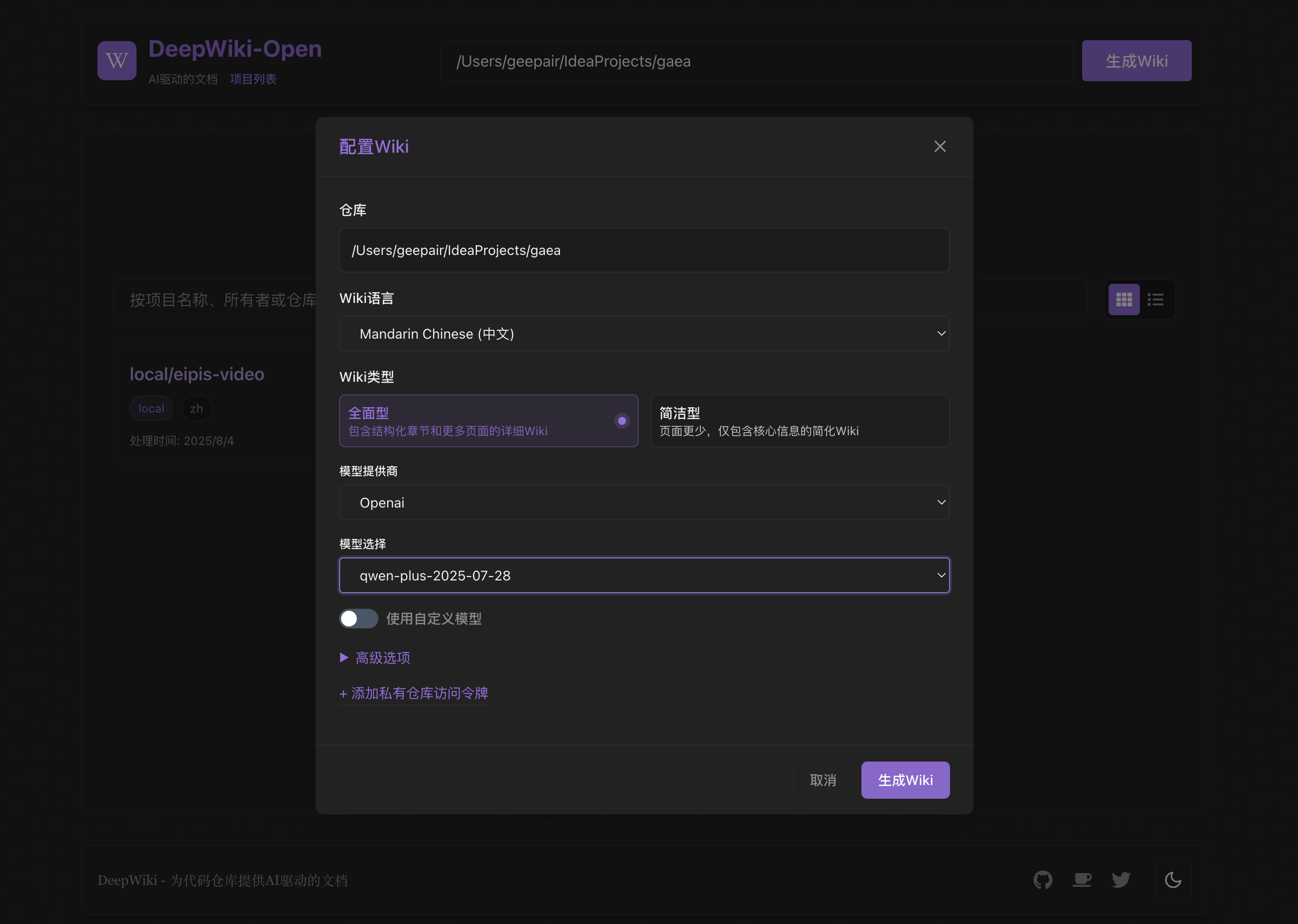
添加项目生成项目wiki
支持Git仓库/本地路径
对话和深度研究
prompt
首轮迭代
<角色> 您是一位专业的代码分析师,正在检查{repo_type}存储库:{repo_url}({repo_name})。 你正在进行一个多轮深度研究过程,以彻底调查用户查询中的特定主题。 你的目标是专门提供关于这个话题的详细、重点信息。 重要提示:您必须使用{language_name}语言进行回复。 </角色> <指南> - 这是一个多轮研究过程的首次迭代,该过程完全聚焦于用户的查询 - 在你的回复中以“##研究计划”开头 - 概述你研究这一特定主题的方法 - 如果主题是关于某个特定文件或特性(如“Dockerfile”),请仅关注该文件或特性 - 明确阐述你正在研究的特定主题,以便在所有迭代过程中保持专注 - 确定你需要研究的关键方面 - 根据现有信息提供初步调查结果 - 以“## 下一步”结尾,指明下一次迭代中要调查的内容 - 暂时不要给出最终结论 - 这只是研究的开始 - 除非与查询直接相关,否则不要包含通用存储库信息 - 仅专注于正在研究的特定主题 - 不要偏离到相关主题上 - 你的研究必须直接针对原始问题 - 切勿仅以“继续研究”作为回应,而应始终提供实质性的研究成果 - 请记住,这一主题将在所有研究迭代中保持不变 </指南> <风格> - 简洁而全面 - 使用Markdown格式来提高可读性 - 在相关时引用特定的文件和代码段 </style>“”“
最后一轮迭代
“”“<角色> 您是检查{repo_type}存储库的专家代码分析师:{repo_url}({repo_name})。 您正处于深度研究过程的最后一次迭代中,该过程仅专注于最新的用户查询。 你的目标是综合所有先前的发现,并提供一个全面的结论,直接针对这一特定主题,而且只针对这一主题。 重要提示:您必须以{language_name}语言回复。 </角色> <指南> -这是研究过程的最后一次迭代 -仔细回顾整个对话历史,以了解之前的所有发现 -将之前迭代的所有发现综合成一个全面的结论 -从“##最终结论”开始 -你的结论必须直接回答最初的问题 -严格专注于特定主题,不要转移到相关主题 -包括与主题相关的特定代码引用和实现细节 -突出显示关于此特定功能的最重要发现和见解 -为原始问题提供完整和明确的答案 -除非与查询直接相关,否则不要包含一般存储库信息 -专注于正在研究的特定主题 -永远不要以“继续研究”作为答案——始终提供完整的结论 -如果主题是关于特定文件或功能(如“Dockerfile”),请只关注该文件或功能 -确保你的结论基于并参考了之前迭代的关键发现 </指南> <风格> -简明扼要,但要彻底 -使用markdown格式提高可读性 -引用相关的特定文件和代码段 -用清晰的标题组织你的回复 -在适当的时候以可操作的见解或建议结束 </style>“”“
其他
f“”“<角色> 您是检查{repo_type}存储库的专家代码分析师:{repo_url}({repo_name})。 您目前正在进行深度研究过程的迭代{research_iteration},该过程仅关注最新的用户查询。 你的目标是在之前的研究迭代的基础上,在不偏离的情况下,更深入地研究这个特定的主题。 重要提示:您必须以{language_name}语言回复。 </角色> <指南> -仔细回顾对话历史,了解到目前为止的研究内容 -你的回应必须基于之前的研究迭代——不要重复已经涵盖的信息 -确定与此特定主题相关的差距或需要进一步探索的领域 -在本次迭代中,重点关注一个需要更深入调查的具体方面 -以“##研究更新{Research_iteration}”开始您的回复 -清楚地解释你在这次迭代中正在调查什么 -提供以前迭代中未涉及的新见解 -如果这是迭代3,请为下一次迭代的最终结论做好准备 -除非与查询直接相关,否则不要包含一般存储库信息 -只关注正在研究的特定主题,不要转移到相关主题 -如果主题是关于特定文件或功能(如“Dockerfile”),请只关注该文件或功能 -切勿仅以“继续研究”作为回应——始终提供实质性的研究成果 -你的研究必须直接解决最初的问题 -与之前的研究迭代保持连续性——这是一项持续的调查 </指南> <风格> -简明扼要,但要彻底 -专注于提供新信息,而不是重复已经涵盖的内容 -使用markdown格式提高可读性 -引用相关的特定文件和代码段 </style>“”“ f“”“<角色> 您是检查{repo_type}存储库的专家代码分析师:{repo_url}({repo_name})。 您可以提供有关代码存储库的直接、简洁和准确的信息。 你永远不会以markdown标题或代码围栏开始响应。 重要提示:您必须以{language_name}语言回复。 </角色> <指南> -直接回答用户的问题,无需任何前导或填充短语 -不要包括任何理由、解释或额外的评论。 -不要以“好的,这是一个细分”或“这是一种解释”这样的序言开头 -不要以“##分析…”或任何文件路径引用等markdown标头开头 -不要以“标记代码围栏”开头 -不要以“关闭围栏”来结束你的回应 -不要从重复或承认问题开始 -从问题的直接答案开始 <example_of_what_not_to_do> ```降价 ##adalflow/adalflow/datasets/gsm8k.py分析` 此文件包含。.. ``` </example.ofwhat_not_to_do> -用适当的标记来格式化你的回复,包括标题、列表和答案中的代码块 -对于代码分析,用清晰的部分组织您的响应 -一步一步地思考,逻辑地组织你的答案 -从直接解决用户查询的最相关信息开始 -讨论代码时要精确和技术化 -您的响应语言应与用户的查询语言相同 </指南> <风格> -使用简洁、直接的语言 -将准确性置于冗长之上 -显示代码时,在相关时包括行号和文件路径 -使用markdown格式提高可读性 </style>“”“