type
Post
status
Published
date
May 12, 2025
slug
summary
tags
开发
思考
category
技术分享
icon
password
1、写在前头,大模型应用开发入门
1.1 模型基础
虽然市面上的大型语言模型(LLMs)种类繁多,但在使用层面大家平等的都是
API调包侠,因此从接口层面来剖析大模型有哪些能力。LLM的接口通常都遵循或类似于 OpenAI 的规范。在与大型模型交互时,除了控制模型输出随机性的参数外(Temperature, TopK…),最核心的参数只有两个:
messages 和 tools。可以说,市面上各种各样的大模型应用,都是基于这两个参数的基础上设计而来。messages-大模型是怎么实现记忆的?
- messages是一个对话数组,其中角色主要有:
- system:代表当前对话的系统指令,一般放提示词
- user:用户指令
- assistant:LLM的回复
- ...:不同厂商会有不同的扩展定义
大模型所谓的对话记忆实际上就是依赖该数组做信息传递,如下图所示,第一轮我告诉我的名字叫xx,第二轮的时候在问他是谁,他已经知道了我的名字,之所以知道因为我在messages的上下文中传递给了他这个信息。
- 使用user传递用户的对话
- 使用system设置系统指令
{ "messages": [ { "role": "user", "content": "你好,我是xx" }, { "role": "assistant", "content": "你好,我是助手" }, { "role": "user", "content": "我是谁?" } ] }
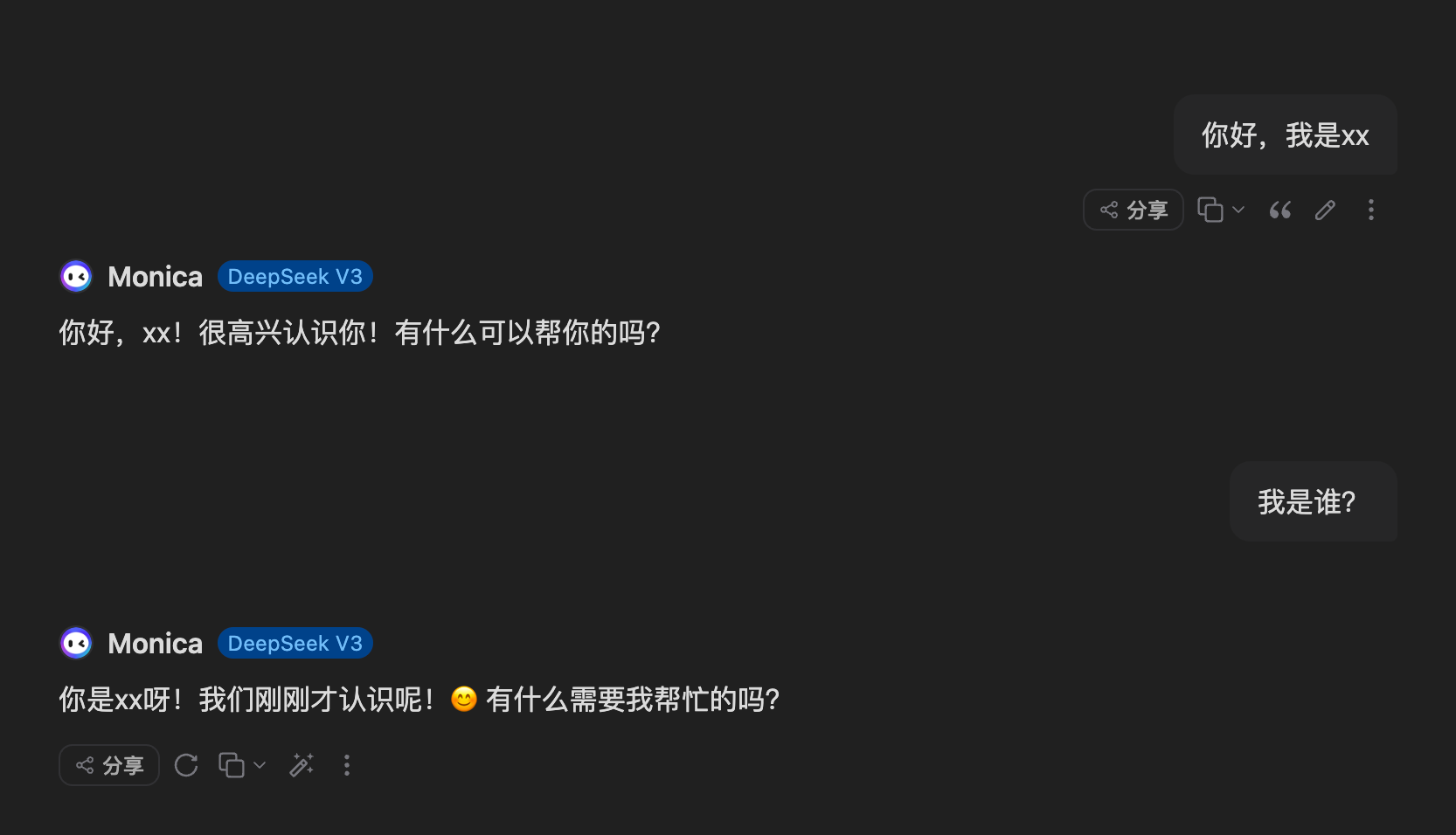
大模型为什么能记住之前的对话?
只是因为后台系统给了他之前的对话,并不是他自己记住。大模型的请求调用就是一个无状态的,取决于每次给的对话内容。
大模型的提示词有什么用?
大模型的提示词可以进一步控制(覆盖)模型的行为,具备高优先级,但存在不稳定性。
第一个重要的大模型范式:检索增强生成,也就是RAG(Retrieval Augmented Generation)
直白的理解为用检索到的知识,来增量生成答案的质量。比如我有一个关于数仓各种问题处理的Q&A,想要做一个问答机器人,这个问答机器人要基于我的Q&A回复用户。这个 检索Q&A -> 基于检索到的Q&A回复用户,这个流程就是一个典型的RAG链路。也显而易见,RAG的最终目标是生成靠谱的答案给到用户。
RAG链路的搭建是很简单,但是效果却很难,从流程里面我们能发现两个关键点:
1.知识库检索召回:这里要解决如何召回最靠谱的答案。
2.LLM基于知识回答:这里要解决的是如何让模型在一堆知识中给出自信准确的回答。
这些都是业界在不断探索的东西,没有所谓的标准答案,只有适合当前业务的最佳方案。
tools-大模型能执行任何工具?
tools也是一个数组,包含了一堆工具集合,核心为工具的作用描述,和工具需要的参数等。
{ "type": "function", "function": { "name": "file_read", "description": "Read file content. Use for checking file contents, analyzing logs, or reading configuration files.", "parameters": { "type": "object", "properties": { "file": { "type": "string", "description": "Absolute path of the file to read" }, "start_line": { "type": "integer", "description": "(Optional) Starting line to read from, 0-based" }, "end_line": { "type": "integer", "description": "(Optional) Ending line number (exclusive)" }, "sudo": { "type": "boolean", "description": "(Optional) Whether to use sudo privileges" } }, "required": ["file"] } } }
接下来就是使用工具,基于工具的回答至少要两次大模型请求调用:
- 将用户的对话和工具一起给到大模型,大模型需要执行的工具以及工具参数;
- 后端系统依据大模型选择结果,去执行对应的工具,拿到结果;
- 再次请求大模型,此时上下文中给到了工具执行结果,大模型基于信息回复;
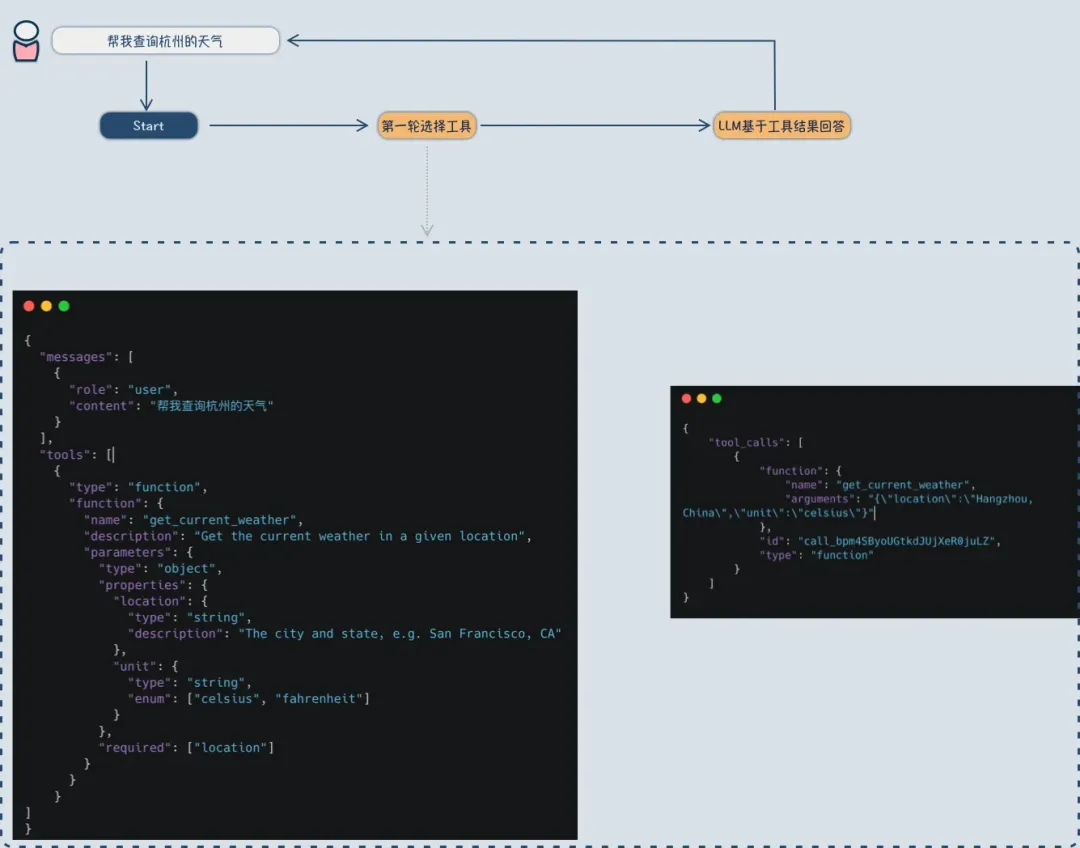
结论
大模型并不能够执行任何工具,但是大模型能够选择接下来要执行的工具。选择后工具由配合的系统来执行获取结果。
第二个重要的大模型范式ReAct(Reason+Act)
LLM 首先思考当前状态和目标,然后选择并调用合适的工具,工具的输出结果又将引导 LLM 进行下一步的思考和行动,如此循环,直到问题解决。
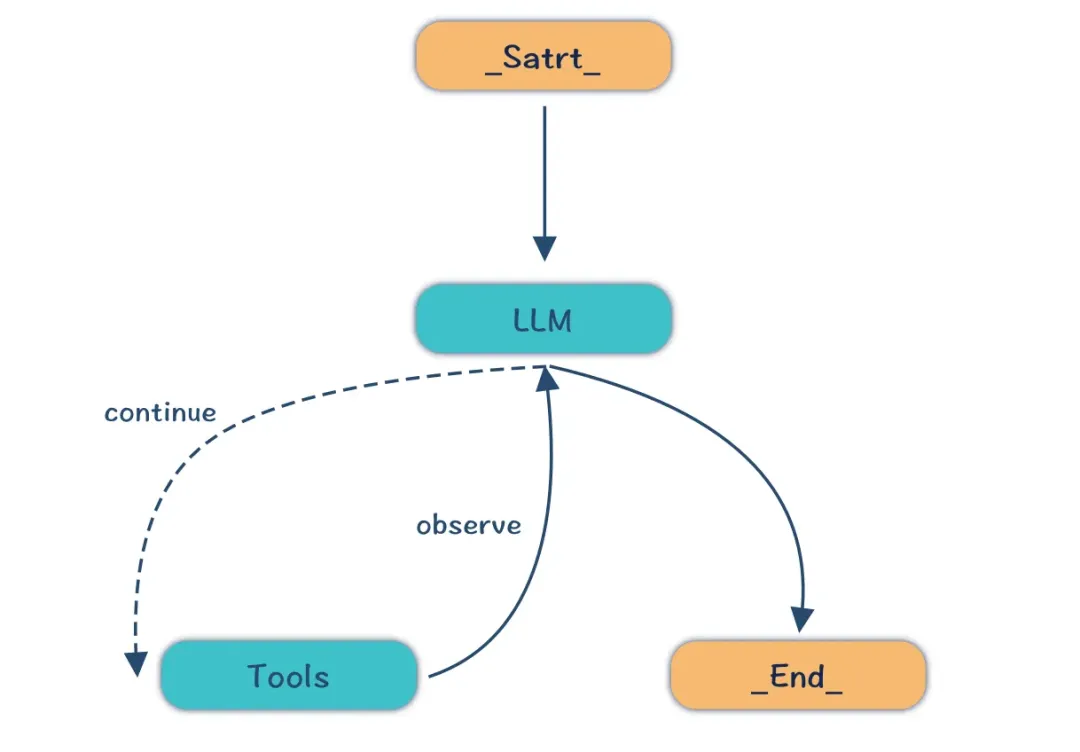
这里需要强调下,大模型的很多范式都是对生活中人类行为的模拟,因此我们也是从生活中的案例来理解大模型。
案例:查询近七日天气并生成文件查看
工具:浏览器,文件管理
- 思考:需要查询近七日天气情况
- 行动:浏览器搜索
- 观察:查看搜索到的天气信息
- 思考:生成文本文档
- 行动:打开记事本写入
- 观察:…
ㅤ | RAG | ReAct |
技术原理 | 结合检索(外部知识库)与生成模型,增强答案的准确性和时效性 | 结合推理(Reasoning)与行动(Action),通过多步骤交互动态完成任务 |
主要目标 | 解决模型知识过时、幻觉问题,提升特定领域问答能力 | 提升复杂任务的完成率,实现动态规划和自主决策 |
关键能力 | 外部知识检索、上下文融合生成 | 推理逻辑链、工具调用(如API、数据库)、多步骤行为规划 |
应用场景 | 知识密集型任务(如专业问答、医疗诊断) | 需要自主决策的复杂任务(如客服流程、多模态交互) |
优缺点对比
RAG
优点:
- 准确性提升:通过检索外部知识库(如文档、数据库),生成结果更依赖事实依据,减少幻觉问
- 时效性强:无需重新训练模型即可更新知识库,适用于动态信息场景(如新闻、研究报告)
- 专业领域适配:可直接集成企业私有数据(如内部手册、客户档案),提升垂直领域实用性
缺点:
- 依赖检索质量:若检索结果不相关或噪声多,生成内容可能偏离用户意图
- 语义理解局限:传统关键词检索(如BM25)难以处理复杂语义,向量检索可能遗漏上下文关联
- 实现复杂度:需构建高效检索系统(如向量数据库、混合搜索策略),开发成本较高
ReAct
优点:
- 动态规划能力:通过推理链(如分解问题、调用工具)自主拆解复杂任务,提升完成率
- 多工具协同:可调用API、数据库、外部服务(如地图、支付接口),扩展模型能力边界
- 交互式修正:支持用户反馈后的实时调整,适用于容错率低的场景(如金融决策)
缺点:
- 实现复杂:需设计推理模板、工具调用接口及容错机制,开发周期长
- 依赖模型推理能力:若模型逻辑推理能力不足,可能导致步骤规划错误
- 响应延迟:多步骤交互可能导致任务执行时间较长
协同应用场景
RAG+ReAct:ReAct动态规划任务步骤,RAG提供实时知识支持(如医疗诊断中先检索病例库,再推理治疗方案)
Agent框架集成:Agent通过RAG获取知识,通过ReAct规划行动,实现类AGI的自主决策
1.2 模型使用
大模型的应用五花八门,但都离不开上述两个核心参数
- 调优提示词:大模型工程中的核心,提示词的优秀与否决定了你是否需要链路上做额外的兜底
- 增加调用次数:将一个任务拆分为多个子任务执行,最后判断结果。这是一种常用的对提示词能力的补充手段,降低单一提示词的复杂性
- 模型微调:通过引入特定业务场景案例,让模型能更好地理解用户的意图和需求
- …
2、Dify入门
2.1 介绍


Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也能参与到 AI 应用的定义和数据运营过程中。
由于 Dify 内置了构建 LLM 应用所需的关键技术栈,包括对数百个模型的支持、直观的 Prompt 编排界面、高质量的 RAG 引擎、稳健的 Agent 框架、灵活的流程编排,并同时提供了一套易用的界面和 API。这为开发者节省了许多重复造轮子的时间,使其可以专注在创新和业务需求上。
核心功能
- 商业模型支持/本地模型推理 Runtime 支持
- 预置应用类型
- Prompt 即服务编排
- Agentic Workflow 特性
- RAG 特性
- Agent 技术
- …
支持模型列表

2.2 安装
克隆Git仓库

git clone https://github.com/langgenius/dify.git cd dify/docker cp .env.example .env
使用Docker安装,拉取最新镜像
docker compose up -d

进入安装界面
http://127.0.0.1/install
2.3 创建一个应用
在 Dify 中,一个“应用”是指基于 GPT 等大语言模型构建的实际场景应用。通过创建应用,你可以将智能 AI 技术应用于特定的需求。它既包含了开发 AI 应用的工程范式,也包含了具体的交付物。
Dify 中提供了五种应用类型:
- 聊天助手:基于 LLM 构建对话式交互的助手
- 文本生成应用:面向文本生成类任务的助手,例如撰写故事、文本分类、翻译等
- Agent:能够分解任务、推理思考、调用工具的对话式智能助手
- 对话流:适用于定义等复杂流程的多轮对话场景,具有记忆功能的应用编排方式
- 工作流:适用于自动化、批处理等单轮生成类任务的场景的应用编排方式

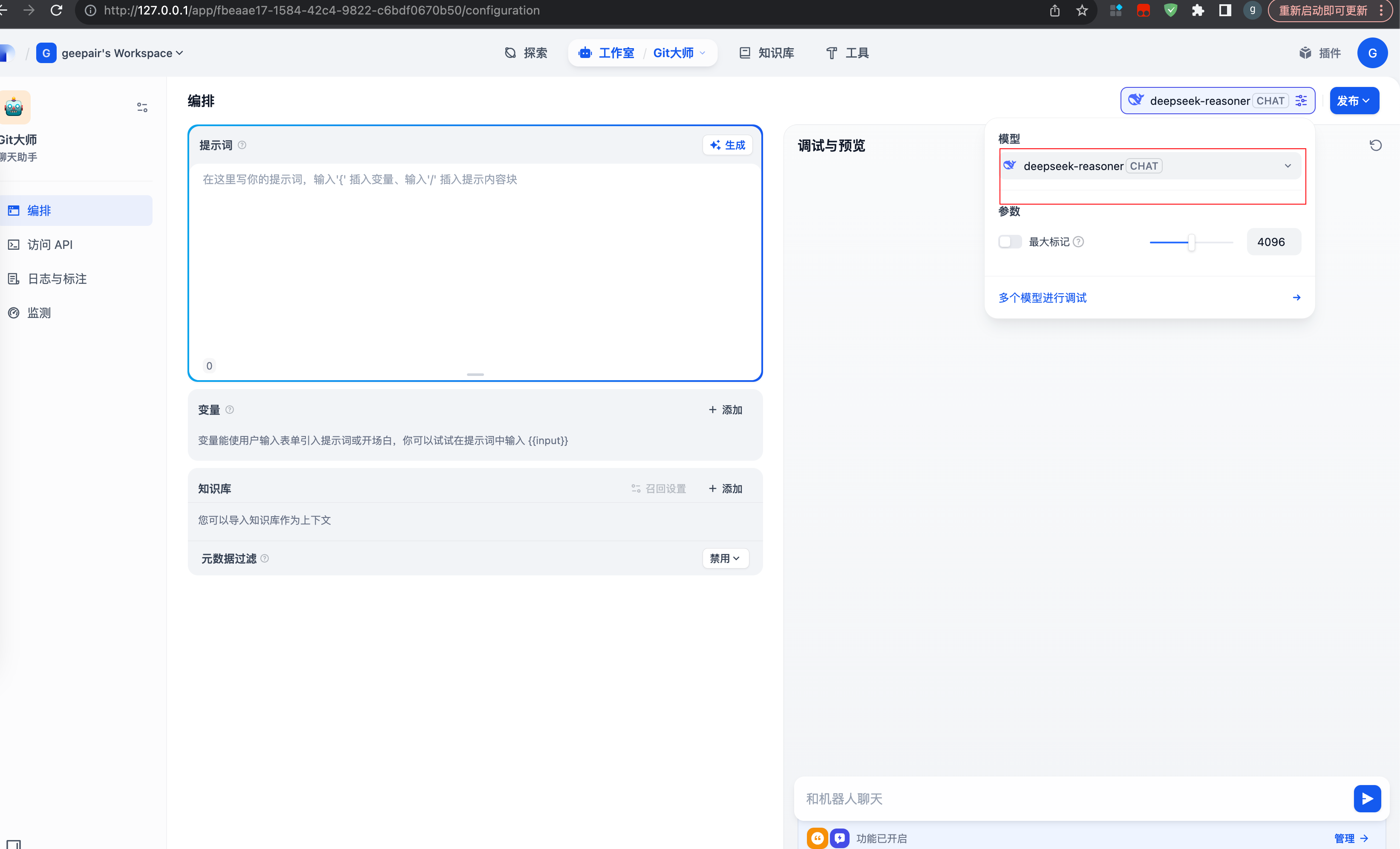
配置模型
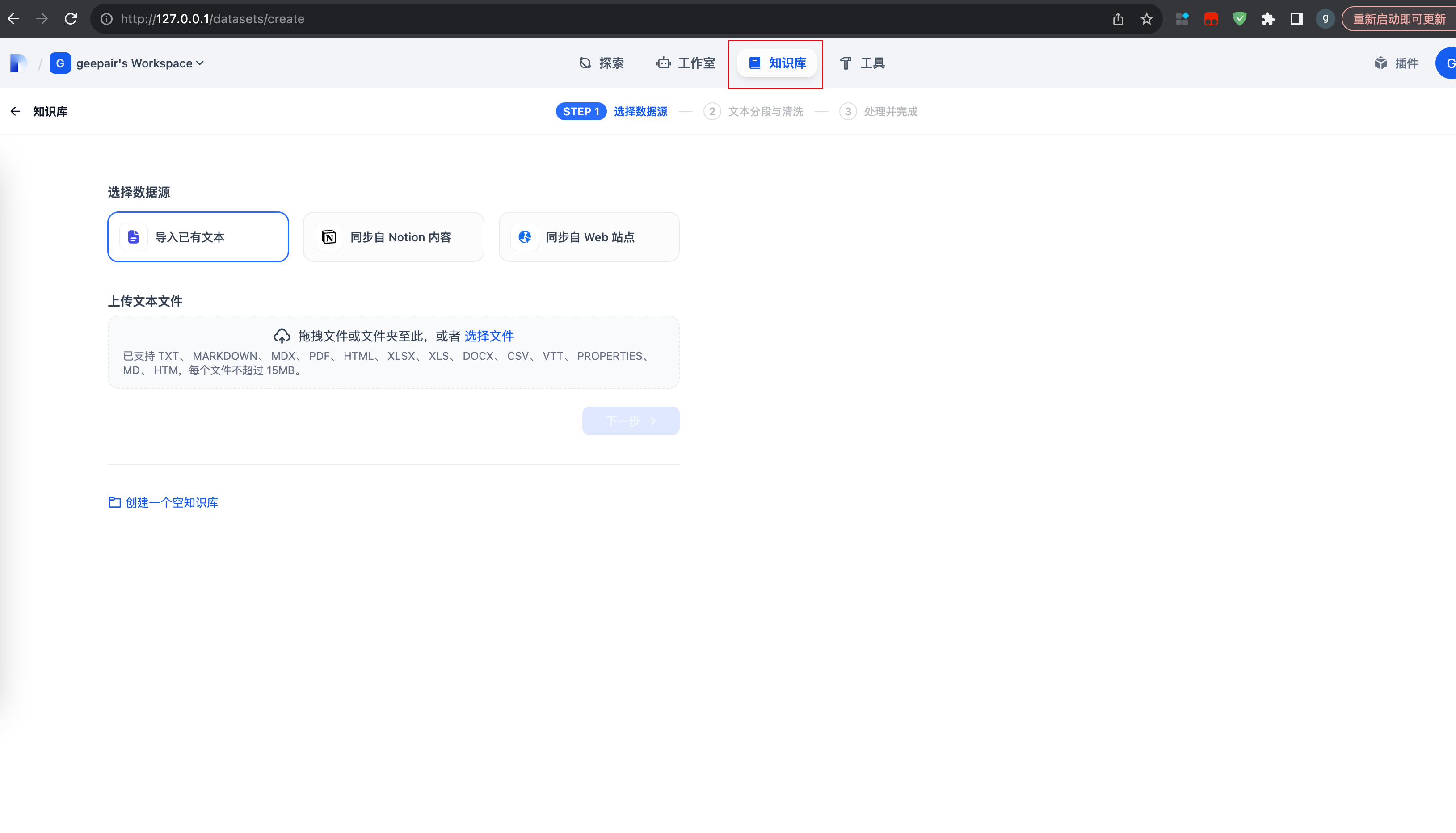
2.4 创建本地知识库
添加Embedding模型
1.为什么要添加Embedding模型?
Embedding模型的作用是将高维数据(如文本、图像)转换为低维向量,这些向量能够捕捉原始数据中的语义信息。常见的应用包括文本分类、相似性搜索、推荐系统等。
我们上传的资料要通过Embedding模型转换为向量数据存入向量数据库,这样回答问题时,才能根据自然语言,准确获取到原始数据的含义并召回,因此我们需要提前将私有数据向量化入库。
2.选择 Embedding 模型
创建知识库