type
Post
status
Published
date
Jul 26, 2023
slug
summary
tags
工具
Python
category
学习思考
icon
password
1.什么是Latent Diffusion模型1.1 简介1.2 相关文档1.3 Diffusion整体结构图1.4.1 文生图过程(整体)1.4.2 使用CLIP模型生成输入文字embedding1.4.3 UNet网络中如何使用文字embedding1.5.1 模型训练过程1.5.2 前向扩散过程1.5.3 反向扩散过程1.5.4 正向训练过程1.5.5 从高斯噪声中生成原始图片(反向扩散过程)1.5.6 U-Net模型结构1.5.7 Diffusion的缺点2. Stable Diffusion2.1.1 图像压缩2.1.2 反向扩散过程2.1.3 改进U-Net结构2.2 完整结构3.安装Stable Diffusion web UI3.1 系统环境(前置条件)3.2 项目结构3.3.1 模型(基础模型)3.3.2 模型站点3.3.3 插件拓展3.3.4 其他(高级)功能4. 演示5. 参考
1.什么是Latent Diffusion模型
1.1 简介
扩散模型(DDPM)
降噪扩散概率模型(Denoising Diffusion Probabilistic Models)
1.2 相关文档

1.3 Diffusion整体结构图

1.4.1 文生图过程(整体)

Diffusion 使用
Text Encoder 生成文字对应的embedding(Text Encoder使用CLIP模型),然后和随机噪声embedding,time step embedding一起作为Diffusion的输入,最后生成理想的图片。- Clip Text用于文本编码(输入:文本,输出:77个token嵌入向量,其中每个向量包含768个维度)
- UNet+Scheduler在信息潜空间中逐步处理/扩散信息(输入:结构化的数字列表,也叫张量tensor,输出:一个经过处理的信息阵列)
- 自编码解码器(Autoencoder Decoder)使用处理过的信息矩阵绘制最终图像的解码器(输入:处理过的信息矩阵,维度为(4, 64, 64),输出:结果图像,各维度为(3,512,512),即(红/绿/蓝,宽,高))

中间的Image Information Creator是由多个UNet模型组成

1.4.2 使用CLIP模型生成输入文字embedding
CLIP(Connecting text and images)在图像及其描述的数据集上进行训练。类似一个数据集,包含图片及其说明
实际上CLIP是根据从网络上抓取的图像及其文字说明进行训练的。CLIP 是图像编码器和文本编码器的组合,它的训练过程可以简化为给图片加上文字说明。首先分别使用图像和文本编码器对它们进行编码。

然后使用余弦相似度刻画是否匹配。最开始训练时,相似度会很低。

然后计算
loss,更新模型参数,得到新的图片embedding和文字embedding
通过在训练集上训练模型,最终得到文字的embedding和图片的embedding

(文本 → tokenize → embedding lookup → transformer) → condition(条件)1.4.3 UNet网络中如何使用文字embedding
实际上是在UNet的每个ResNet之间添加一个Attention,而Attention一端的输入便是文字embedding

ResNet块没有直接看到文本内容,而是通过注意力层将文本在latents中的表征合并起来,然后下一个ResNet就可以在这一过程中利用上文本信息。

1.5.1 模型训练过程

- 前向扩散过程(Forward Diffusion Process) 图片中添加噪声
- 反向扩散过程(Reverse Diffusion Process) 去除图片中的噪声
1.5.2 前向扩散过程
不断往输入图片中添加高斯噪声

1.5.3 反向扩散过程
反向扩散过程是将噪声不断还原为原始图片

1.5.4 正向训练过程

- 每一个训练样本选择一个随机时间步长
- 将time step t对应的高斯噪声应用到图片中
- 将time step转化为对应embedding

1.5.5 从高斯噪声中生成原始图片(反向扩散过程)

1.5.6 U-Net模型结构


升/降维
图片noise/denoise
1.5.7 Diffusion的缺点
在反向扩散过程中需要把完整尺寸的图片输入到U-Net,这使得当图片尺寸以及time step t足够大时,Diffusion会非常的慢。

Stable Diffusion会先训练一个
自编码器,来学习将图像压缩成低维表示。- 通过训练好的编码器
E,可以将原始大小的图像压缩成低维的latent data(图像压缩)
- 通过训练好的解码器
D,可以将latent data还原为原始大小的图像
Diffusion扩散模型就是在
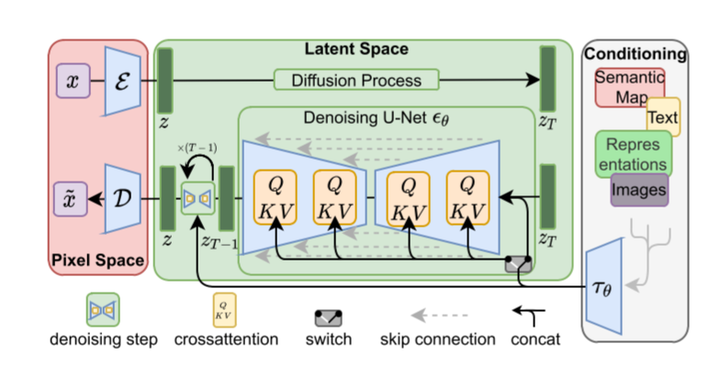
原图X上进行的操作,而Stale Diffusion是在压缩后的图像Z上进行操作。2. Stable Diffusion
2.1.1 图像压缩
Stable Diffusion原来的名字叫“Latent Diffusion Model”(LDM),很明显就是扩散过程发生潜空间中(latent space),其实就是对图片做了压缩,这也是Stable Diffusion比Diffusion速度快的原因。

2.1.2 反向扩散过程

支持了文本的输入,对U-Net的结构做了修改,使得每一轮去噪过程中文本和图像相关联
2.1.3 改进U-Net结构

反向扩散过程中输入文本和初始图像Z需要经过T轮的U-Net网络(T轮去噪过程),最后得到输出Z0
,解码后便可以得到最终图像。由于要处理文本向量,因此必然要对U-Net网络进行调整,这样才能使得文本和图像相关联。
单轮U-Net

- Semantic Map:表示处理的是通过语义生成图像的任务
- Text:表示的就是文字生成图像的任务
- Representations:表示的是通过语言描述生成图像
- Images:表示的是根据图像生成图像
我们只考虑输入是Text,因此首先会通过模型CLIP模型生成文本向量,然后输入到U-Net网络中的多头Attention(Q, K, V)。

2.2 完整结构

3.安装Stable Diffusion web UI
3.1 系统环境(前置条件)
依赖:Python,Git
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
3.2 项目结构
. ├── models # 下载的模型存放在此处 │ ├── Lora # Lora 模型 │ │ ├── lyriel_v13.safetensors # 模型文件 │ │ └── ... # 其他模型文件 │ ├── Stable-diffusion # 基础模型 │ │ ├── v1-5-pruned.ckpt # 模型文件 │ │ └── ... # 其他模型文件 │ ├── VAE # VAE 模型 │ │ ├── vae-ft-mse-840000-ema-pruned.safetensors # 模型文件 │ │ └── ... # 其他模型文件 │ └── ... # 其他 ├── outputs # ️ 图片输出位置 │ ├── img2img-grids # 网格图(2x2) │ ├── img2img-images # 图生图 │ ├── txt2img-grids # 网格图(2x2) │ ├── txt2img-images # 文字生图 │ └── ... # 其他 ├── repositories # ️ 缓存仓库,可删除 ├── venv # ️ 虚拟环境,一个独立的 Python 运行环境,可删除 ├── webui-user.bat # ⚙️ Windows 启动脚本用户配置 ├── webui-user.sh # ⚙️ Linux,Mac 启动脚本用户配置 ├── webui.bat # Windows 启动脚本 ├── webui.sh # Linux,Mac 启动脚本 └── ... # 其他
3.3.1 模型(基础模型)
官方模型:
- Stable DIffusion 1.4 (sd-v1-4.ckpt)
- Stable Diffusion 1.5 (v1-5-pruned-emaonly.ckpt)
- Stable Diffusion 1.5 Inpainting (sd-v1-5-inpainting.ckpt)
Stable Diffusion 2.0 和 2.1 需要模型和配置文件,生成图像时图像宽度和高度需要设置为 768 或更高:
- Stable Diffusion 2.0 (768-v-ema.ckpt)
- Stable Diffusion 2.1 (v2-1_768-ema-pruned.ckpt)
3.3.2 模型站点

模型格式一般使用
.ckpt 或 .safetensors (大模型)作为文件扩展名- LoRA 模型(LoRA: Low-Rank Adaptation of Large Language Models):LoRA 是一种在大型语言模型的预训练权重基础上,注入可训练秩分解矩阵,从而减少可训练参数数量,提高训练吞吐量和减少 GPU 内存需求的方法。相比于完全微调模型,LoRA 可以在不增加推理延迟的情况下,达到相当甚至更好的模型性能(简单来说它就是基础模型的微调模型,比如修改风格为国风,水墨风等)。
- VAE(Variational Autoencoder):VAE 代表变分自动编码器。它是神经网络模型的一部分,可对来自较小潜在空间的图像进行编码和解码(极大减少了显存),从而使计算速度更快。
- Model 与 Lora 的关系(以书本世界为例):
- Model:百科全书
- LoRA: 百科全书中的一个额外条目,作为一个“便利贴”塞进其中。
.ckpt与.safetensors:它们都是一种用于分发模型的文件格式。.ckpt:是很多包含 Python 代码的压缩文件,利用它们就像解压缩一样简单。因包含大量代码,意味着它可能包含恶意代码,加载未知不信任来源的 .ckpt 文件,很可能会危害你的计算机。.safetensors:只包含生成所需的数据,更难被利用。不包含代码,所以加载 .safetensors 文件也更安全和快速。
3.3.3 插件拓展
- prompt提示/tag自动完成
- ControlNet
- Additional Networks
- LoRA
3.3.4 其他(高级)功能
- 训练(Textual Inversion/Hypernetwork/dreambooth/loRA)
- (超级)模型融合/转换
- 图片信息/标签器
- …
4. 演示
5. 参考
相关文档和视频介绍


论文参考