type
Post
status
Published
date
Jun 12, 2024
slug
summary
tags
开发
工具
category
技术分享
icon
password
1 Java缓存主流框架介绍1.1 Spring Cache1.2 Guava Cache1.3 Caffeine1.4 J2Cache1.5 EhCache1.6 JetCache1.7 其他2 JSR-1072.1 什么是JSR-107?2.2 JAVA缓存概念2.2.1 Java缓存的一些能力2.2.2 值存储和引用存储2.2.3 缓存与Map的区别2.3 JCache引入使用3 Guava Cache3.1 支持缓存记录的过期设定3.2 支持缓存容量限制与不同淘汰策略3.3 支持集成数据源能力3.4 支持更新锁定能力3.5 提供了缓存相关的一些监控统计3.6 适用场景3.7 淘汰策略4 Caffeine4.1 异步策略4.2 ConcurrentHashMap优化特性4.3 淘汰算法W-LFU4.4 Caffeine使用5 Spring Cache注解6 参考
1 Java缓存主流框架介绍
1.1 Spring Cache
Spring Cache 是 Spring 提供的一整套的缓存解决方案。虽然它本身并没有提供缓存的实现,但是它提供了一整套的接口和代码规范、配置、注解等,这样它就可以整合各种缓存方案了,比如 Redis、Ehcache,我们也就不用关心操作缓存的细节。
特性
- 基于AOP与方法级注解实现自动缓存操作, 不需要手动进行缓存的写入与清除操作
- 官方提供了多种开箱即用的缓存实现(EhCache / Redis / Caffeine / Map 等), 也支持自定义缓存实现
Spring Cache是 Spring-Context 中的一个缓存抽象, 它主要封装一套注解:
@Cacheable, @CacheEvict, @CachePut, @Caching, @CacheConfig, 配合Spring的AOP能力, 对接口层面的缓存提供了统一的规范, 并实现了切面中的复杂逻辑, 但是它底层并没有实现具体的缓存逻辑, 需要集成其他缓存框架来使用, 底层只需要实现他的 Cache 接口即可1.2 Guava Cache
GuavaCache是 Google 开源的一级缓存框架, 可以理解为 ConcurrentHashMap 的增强版, 使其适合用来作为一个缓存集合

特性
- 基于ConcurrentHashMap, 支持高并发下的线程安全, 性能也做了优化
- 提供CacheBuilder, 简化缓存操作对象的创建, 支持设置自定义的CacheLoader用来加载数据至缓存
- 使用软引用与弱引用机制, 保障GC安全
- 支持key移除监听, 支持同步监听与异步监听, 在key移除后执行一些逻辑
- 支持多个缓存清除策略: 存活时间 / 最大容量 / 主动清除 / 软弱引用
- 支持获取指定缓存集合的命中率等指标
GuavaCache的出现其实是简化了日常的本地缓存使用方式, 在这之前, 我们想要做本地缓存一般都是基于HashMap等方式自行封装缓存操作工具, 自己维护 缓存策略 / 淘汰策略, 性能不没有保障, 内存泄漏的风险也很高, 而 GuavaCache 帮大家将这些封装打包起来了, 还支持了许多额外的扩展功能, 最终提供一个开箱即用的缓存工具包, 用户不需要再去关心里面的实现细节, 内存/性能问题也得到了保障。总的来说, GuavaCache是一个十分优秀的轻量级的本地缓存框架, 可以直接使用
1.3 Caffeine
Caffeine 是以 GuavaCache 为原型而开发的一个本地缓存框架, 相对GuavaCache, 它有更高的性能与命中率, 更强大的功能, 更灵活的配置方式(Guava Cache Plus)
特性
- 具备GuavaCache几乎所有特性, 并提供了适配器, 方便Guava用户迁移至Caffeine
- 通过异步维护/异步通知/异步刷新等方式, 达到了极致的读写性能
- 实现了JSR-107 JCache接口API
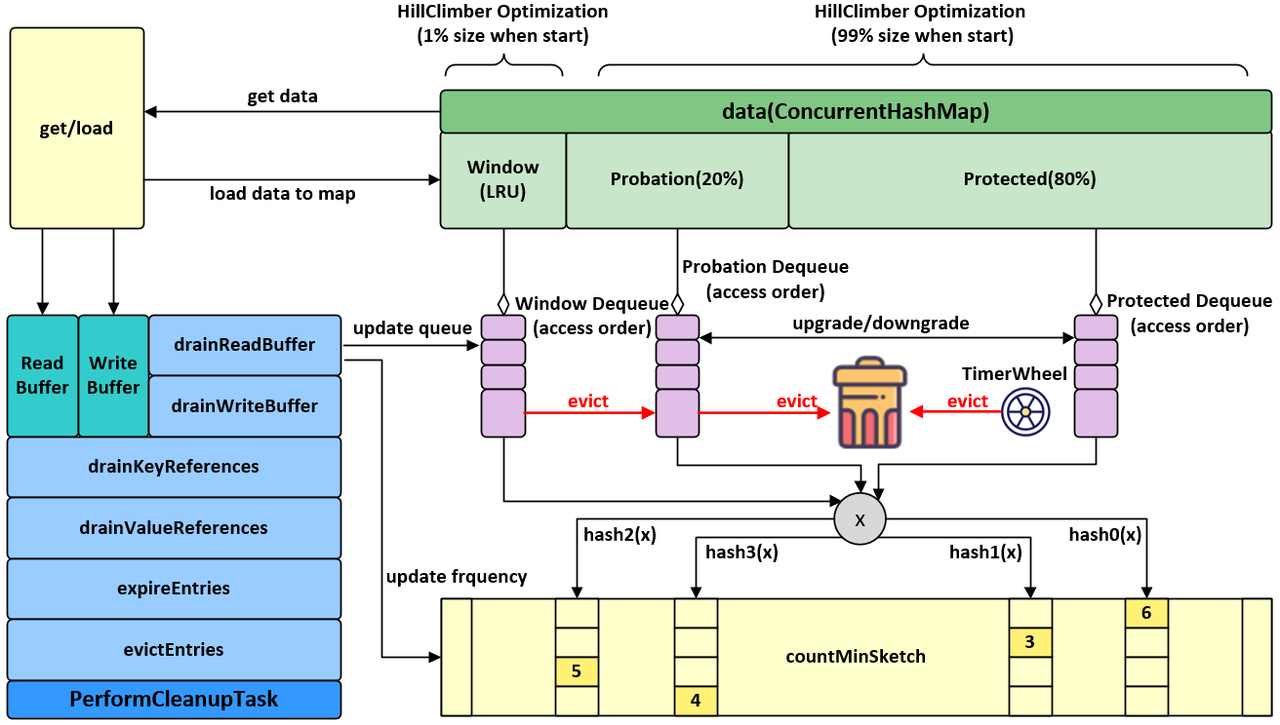
我们可以将Caffeine看做是GuavaCache的升级版, 它主要在性能和命中率上碾压了Guava, 这有两方面造成, 一是Caffeine将所有阻塞读写的操作全部通过ForkJoinPool实现异步处理, 二是Caffeine优化了缓存淘汰算法(W-TinyLFU), 除此之外, 在一些细节的实现逻辑上, Caffeine也做了一定的调整, 比如: 替换通知 / null值处理 / 统计方式.
1.4 J2Cache
J2Cache是 OSChina 开源的一个两级缓存框架, 采用固定的 一级 + 二级缓存 的模式, 从一开始就是为了解决两级缓存一致性的问题

1.5 EhCache
EhCache是一个轻量级开源的缓存框架, Hibernate使用的默认缓存框架就是EhCache, 它支持多种缓存模型, 将缓存管理在 堆内 / 堆外 / 磁盘 / 远程 多地
特性
- 实现了JSR107的规范, 并支持无缝集成 SpringCache/Hibernate/Tomcat等
- 轻量级核心, 除slf4j外无其他依赖
- 支持 堆内内存 / 堆外内存 / 磁盘 / 远程缓存服务 三层存储
- 支持多种缓存模型: 独立缓存 / 分布式缓存 / 复制式缓存
- 独立缓存: 每个应用实例在本地维护缓存, 意味着在其中一个实例中修改了缓存, 会导致与其他实例的缓存信息不一致
- 分布式缓存: 每个应用实例本地维护少量热点缓存, 并有一个远程缓存服务端来管理更多的缓存信息, 本地缓存未命中时则请求远程服务获取缓存信息, 这解决了缓存空间的问题, 但也无法保证实例间的本地缓存一致性
- 复制式缓存: 通过引入第三方事件通知机制(rmi/jgroup/jms等), 来同步各个实例间的本地缓存(包含内存/硬盘), 这意味着每个实例都需要维护一份完整的缓存数据在内存/硬盘中, 开销不小, 并且大数据量下的频繁变更也容易导致各实例间的数据不致性
EhCache是一个非常老牌的缓存框架了, 它可以说是缓存全家桶, 从本地内存缓存到硬盘缓存到远程缓存服务一整套全部自己实现, 与其说他是一个框架, 他更像是一个企业级应用缓存解决方案以及实现, 但是查看其官方网站, 便被EhCache的庞大体系所震惊.
总的来说, 虽然EhCache核心包极度轻量, 但过于复杂的配置与使用方式项使得在项目开发中难以灵活运用, 况且其大部分功能在实际开发场景中难有用武之地, 如缓存落盘等
1.6 JetCache
JetCache 是阿里开源的通用缓存访问框架, 它统一了多级缓存的访问方式, 封装了类似于SpringCache的注解, 以及GuavaCache类似的Builder, 来简化项目中使用缓存的难度
特性
- 提供统一的, 类似jsr-107风格的API访问Cache, 并可通过注解创建并配置Cache实例
- 提供类似SpringCache风格的注解, 实现声明式的方法缓存, 并支持TTL和两级缓存
- 支持缓存自动刷新与加载保护, 防止高并发下缓存未命中时打爆数据库
- 支持缓存的统计指标
JetCache的定位与SpringCache类似, 它没有去实现具体的缓存实现, 而是对现有的缓存框架进行抽象, 并提供统一的访问入口, 而且JetCache提供了比SpringCache更强大的接口缓存注解, 除此之外, 还提供了CacheBuilder / 缓存对象注解, 可以说将开发过程中所有使用缓存的场景都覆盖到了, 属于开发效率型框架
1.7 其他
……
2 JSR-107
2.1 什么是JSR-107?
JSR是Java Specification Requests的缩写,意思是Java规范提案。2012年10月26日JSR规范委员会发布了JSR 107(JCache API)的首个早期草案。JCache规范定义了一种对Java对象临时在内存中进行缓存的方法,包括对象的创建、共享访问、假脱机(spooling)、失效、各JVM的一致性等,可被用于缓存JSP内最经常读取的数据。
2.2 JAVA缓存概念
- Java缓存的一些能力
- 值存储和引用存储
- 缓存和Map
2.2.1 Java缓存的一些能力
- 提供一些特殊的缓存能力。例如缓存JAVA对象
- 定义出通用的抽象类和工具。例如:spring的
Cache和CacheManager这两个接口
- 简单易用
- 对业务的侵略性低
- 提供进程内和分布式的缓存实现
- 支持按值或者引用来缓存数据
- 支持注解来实现缓存功能
2.2.2 值存储和引用存储
值存储:每次获取缓存都会深拷贝一份,以至于修改值不会有副作用
引用存储:共同维护一份缓存,修改值会产生副作用
2.2.3 缓存与Map的区别
相同点:
- 通过key存储数据
- key唯一
- 使用可变对象作为key需要特别小心
- 比较相等可以重写equals和hash方法
不同点:
- 缓存存储的key和values都不能为空
- 缓存可以过期
- 空间不足的时候,某些缓存有可能会被删除,当内存空间不足,可以运行某些策略释放一些旧的缓存,例如:LRU策略
- 实现CAS操作,需要实现equals方法
- 序列化keys和values
- 缓存可以选择不同的存储实体,以及不同的存储类型(值存储或者存储引用)
- 可以校验安全性,抛出异常
2.3 JCache引入使用
在maven项目中引入以下两个项目
cache-api和cache-ri-impl<!-- JCache --> <dependency> <groupId>javax.cache</groupId> <artifactId>cache-api</artifactId> <version>1.1.0</version> </dependency> <dependency> <groupId>org.jsr107.ri</groupId> <artifactId>cache-ri-impl</artifactId> <version>1.1.1</version> </dependency>
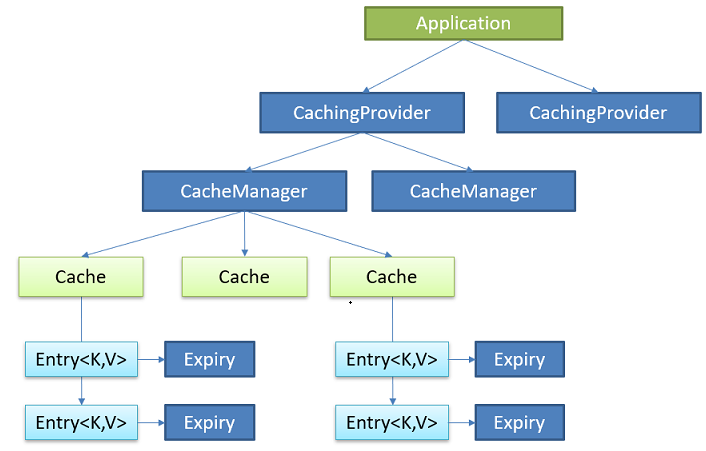
JavaCache(简称JCache)定义了Java标准的api。JCache主要定义了5个接口来规范缓存的生命周期
- CacheingProvider:管理多个CacheManager,制定建立,配置,请求机制
- CacheManager:管理多个Cache,制定建立,配置,请求机制,只有一个对应的CacheProvider
- Cache:对缓存操作,只有一个对应的CacheManager
- Cache.Entry:Cache接口的内部接口,真正的存储实体
- ExporyPolicy:控制缓存的过期时间。
JSR107 将一些常用的 API 方法封装为注解,利用注解来简化编码的复杂度,降低缓存对于业务逻辑的侵入性,使得业务开发人员更加专注于业务本身的开发。
注解 | 说明 |
@CacheResult | 将指定的 key 和 value 存入到缓存容器中 |
@CachePut | 更新缓存容器中对应 key 的缓存内容 |
@CacheRemove | 移除缓存容器中对应 key 的缓存记录 |
@CacheRemoveAll | 移除缓存容器中的所有缓存记录 |
@CacheKey | 指定缓存的 key,用于方法参数前面 |
@CacheValue | 指定缓存的 value,用于方法参数前面 |
JCache使用示例
public static void jCache() throws InterruptedException { // 创建缓存管理器 CacheManager manager = Caching.getCachingProvider("org.jsr107.ri.spi.RICachingProvider").getCacheManager(); // 创建一个配置管理器 Configuration<Integer, String> configuration = new MutableConfiguration<Integer, String>() .setTypes(Integer.class, String.class) .setStoreByValue(false) .setExpiryPolicyFactory(CreatedExpiryPolicy.factoryOf(new Duration(TimeUnit.SECONDS, 5))); // 创建缓存对象 Cache<Integer, String> cache = manager.createCache("JCache1", configuration); cache.put(1, "guazi1"); System.out.println(cache.get(1)); cache.put(2, "guazi2"); Thread.sleep(6000); System.out.println(cache.get(2)); }
JCache使用示例(注解)
@EnableCaching @Configuration public class JCacheConfig { @Bean public JCacheCacheManager jCacheCacheManager() { // 创建缓存管理器 CacheManager manager = Caching.getCachingProvider("org.jsr107.ri.spi.RICachingProvider").getCacheManager(); // 创建一个配置管理器 MutableConfiguration<Integer, String> configuration = new MutableConfiguration<Integer, String>() .setTypes(Integer.class, String.class) .setStoreByValue(false) .setExpiryPolicyFactory(CreatedExpiryPolicy.factoryOf(new Duration(TimeUnit.SECONDS, 5))); // 创建缓存对象 Cache<Integer, String> cache = manager.createCache("JCache2", configuration); // jCache JCacheCacheManager jCache = new JCacheCacheManager(); jCache.setCacheManager(manager); return jCache; } } @Service public class JCacheServiceImpl { @CacheResult(cacheName = "JCache2") public String jCache2Query(@CacheKey Integer id) { System.out.println("jCache2Query, id: " + id); return "result: " + id; } @CachePut(cacheName = "JCache2") public String jCache2Update(@CacheKey Integer id, @CacheValue String newVal) { System.out.println("jCache2Update, id: " + id + ", newVal: " + newVal); return newVal; } @CacheRemove(cacheName = "JCache2") public void jCache2Delete(@CacheKey Integer id) { System.out.println("JCache2Delete, id: " + id); } } @RestController public class JCacheController { @Resource private JCacheServiceImpl jCacheService; // http://127.0.0.1:8080/jcache?id=1 @RequestMapping("/jcache") public Integer hello(@RequestParam Integer id) { jCacheService.jCache2Query(id); jCacheService.jCache2Update(id, "guazi1"); jCacheService.jCache2Query(id); return id; } }
3 Guava Cache
引入依赖
<!-- Guava --> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>32.1.3-jre</version> </dependency>
容器创建使用CacheBuilder
CacheBuilder中常见的属性方法
方法 | 含义说明 |
newBuilder | 构造出一个Builder实例类 |
initialCapacity | 待创建的缓存容器的初始容量大小(记录条数) |
maximumSize | 指定此缓存容器的最大容量(最大缓存记录条数) |
maximumWeight | 指定此缓存容器的最大容量(最大比重值),需结合weighter方可体现出效果 |
expireAfterWrite | 设定过期策略,按照数据写入时间进行计算 |
expireAfterAccess | 设定过期策略,按照数据最后访问时间来计算 |
weighter | 入参为一个函数式接口,用于指定每条存入的缓存数据的权重占比情况。这个需要与maximumWeight结合使用 |
refreshAfterWrite | 缓存写入到缓存之后 |
concurrencyLevel | 用于控制缓存的并发处理能力,同时支持多少个线程并发写入操作 |
recordStats | 设定开启此容器的数据加载与缓存命中情况统计 |
业务层使用Cache
接口名称 | 具体说明 |
get | 查询指定key对应的value值,如果缓存中没匹配,则基于给定的Callable逻辑去获取数据回填缓存中并返回 |
getIfPresent | 如果缓存中存在指定的key值,则返回对应的value值,否则返回null(此方法不会触发自动回源与回填操作) |
getAllPresent | 针对传入的key列表,返回缓存中存在的对应value值列表(不会触发自动回源与回填操作) |
put | 往缓存中添加key-value键值对 |
putAll | 批量往缓存中添加key-value键值对 |
invalidate | 从缓存中删除指定的记录 |
invalidateAll | 从缓存中批量删除指定记录,如果无参数,则清空所有缓存 |
size | 获取缓存容器中的总记录数 |
stats | 获取缓存容器当前的统计数据 |
asMap | 将缓存中的数据转换为ConcurrentHashMap格式返回 |
cleanUp | 清理所有的已过期的数据 |
3.1 支持缓存记录的过期设定
Guava Cache不但支持设定过期时间,还支持选择是根据插入时间进行过期处理(创建过期)、或者是根据最后访问时间进行过期处理(访问过期)。
过期策略 | 具体说明 |
创建过期 | 基于缓存记录的插入时间判断。比如设定10分钟过期,则记录加入缓存之后,不管有没有访问,10分钟时间到则过期 |
访问过期 | 基于最后一次的访问时间来判断是否过期。比如设定10分钟过期,如果缓存记录被访问到,则以最后一次访问时间重新计时;只有连续10分钟没有被访问的时候才会过期,否则将一直存在缓存中不会被过期。 |
基于创建时间过期
public static Cache<String, User> createUserCacheAfterWrite() { return CacheBuilder.newBuilder() .expireAfterWrite(30L, TimeUnit.MINUTES) .build(); }
基于访问时间过期
public static Cache<String, User> createUserCacheAfterAccess() { return CacheBuilder.newBuilder() .expireAfterAccess(30L, TimeUnit.MINUTES) .build(); }
3.2 支持缓存容量限制与不同淘汰策略
作为内存型缓存,必须要防止出现内存溢出的风险。Guava Cache支持设定缓存容器的最大存储上限,并支持根据缓存记录条数或者基于每条缓存记录的权重(后面会具体介绍)进行判断是否达到容量阈值。
实际使用的时候,在创建缓存容器的时候指定容量上限与淘汰策略。
当容量触达阈值后,支持根据FIFO + LRU策略实施具体淘汰处理以腾出位置给新的记录使用。
淘汰策略 | 具体说明 |
FIFO | 根据缓存记录写入的顺序,先写入的先淘汰 |
LRU | 根据访问顺序,淘汰最久没有访问的记录 |
限制缓存记录条数
public static Cache<String, User> createUserCacheMaximumSize() { return CacheBuilder.newBuilder() .maximumSize(10000L) .build(); }
限制缓存记录权重
public static Cache<String, User> createUserCacheMaximumWeight() { return CacheBuilder.newBuilder() .maximumWeight(10000L) .weigher((key, value) -> value.toString().length()) .build(); }
3.3 支持集成数据源能力
Guava Cache作为一个封装好的缓存框架,是一个典型的穿透型缓存。正常业务使用缓存时通常会使用旁路型缓存,即先去缓存中尝试查询获取数据,如果获取不到则会从数据库中进行查询并加入到缓存中;而为了简化业务端使用复杂度,Guava Cache支持集成数据源,业务层面调用接口查询缓存数据的时候,如果缓存数据不存在,则会自动去数据源中进行数据获取并加入缓存中。
public static User findUser(Cache<String, User> cache, String key) { try { return cache.get(key, () -> { System.out.println("缓存不存在..."); return findUserFromDb(key); }); } catch (Exception e) { e.printStackTrace(); } return null; } public static LoadingCache<String, User> createUserCacheWithLoader() { return CacheBuilder.newBuilder() .build(new CacheLoader<String, User>() { @Override public User load(String key) { System.out.println("缓存不存在..."); return findUserFromDb(key); } }); }
执行顺序:Callable > CacheLoader
3.4 支持更新锁定能力
当缓存不可用时,仅持锁的线程负责从数据库中查询数据并写入缓存中,其余请求重试时先尝试从缓存中获取数据,避免所有的并发请求全部同时打到数据库上。
作为穿透型缓存的保护策略之一,Guava Cache自带了并发锁定机制,同一时刻仅允许一个请求去回源获取数据并回填到缓存中,而其余请求则阻塞等待,不会造成数据源的压力过大。
3.5 提供了缓存相关的一些监控统计
支持查看缓存数据的加载或者命中情况统计
Guava Cache的统计信息封装为CacheStats对象进行承载,主要包含一下几个关键指标项:
指标 | 含义说明 |
hitCount | 命中缓存次数 |
missCount | 没有命中缓存次数(查询的时候内存中没有) |
loadSuccessCount | 回源加载的时候加载成功次数 |
loadExceptionCount | 回源加载但是加载失败的次数 |
totalLoadTime | 回源加载操作总耗时 |
evictionCount | 删除记录的次数 |
public static Cache<String, User> findUserCacheWithLoader() { LoadingCache<String, User> cache = CacheBuilder.newBuilder() .recordStats() .build(new CacheLoader<String, User>() { @Override public User load(String key) throws Exception { System.out.println("缓存不存在..."); User user = findUserFromDb(key); if (user == null) { System.out.println("用户不存在"); } return user; } }); return cache; } Cache<String, User> userCacheWithLoader = findUserCacheWithLoader(); System.out.println(userCacheWithLoader.stats());
3.6 适用场景
作为一款纯粹的本地缓存框架,Guava Cache具备本地缓存该有的优势,也无可避免的存在着本地缓存的弊端。
维度 | 简要概述 |
优势 | 基于空间换时间的策略,利用内存的高速处理效率,提升机器的处理性能,减少大量对外的IO请求交互,比如读取DB、请求外部网络、读取本地磁盘数据等等操作。 |
弊端 | 整体容量受限,可能对本机内存造成压力。此外,对于分布式多节点集群部署的场景,缓存更新场景会出现缓存漂移问题,导致各个节点之间的缓存数据不一致。 |
- 数据读多写少且对一致性要求不高的场景
- 对性能要求极其严苛的场景
- 简单的本地数据缓存,作为HashMap/ConcurrentHashMap的替代品
3.7 淘汰策略
被动淘汰
- 基于数据量(size或者weight)
- 基于过期时间
- 基于引用
主动淘汰
接口名称 | 含义描述 |
invalidate(key) | 删除指定的记录 |
invalidateAll(keys) | 批量删除给定的记录 |
invalidateAll() | 清空整个缓存容器 |
4 Caffeine
基于Guava cache基础上孵化而来的改良版本,众多的特性与设计思路都完全沿用了Guava Cache相同的逻辑,且提供的接口与使用风格也与Guava Cache无异。
4.1 异步策略
Caffeine则采用了异步处理的策略,get请求中虽然也会触发淘汰数据的清理操作,但是将清理任务添加到了独立的线程池中进行异步的不会阻塞 get 请求的执行与返回,这样大大缩短了get请求的执行时长,提升了响应性能。
除了对自身的异步处理优化,Caffeine还提供了全套的Async异步处理机制,可以支持业务在异步并行流水线式处理场景中使用以获得更加丝滑的体验。
Caffeine完美的支持了在异步场景下的流水线处理使用场景,回源操作也支持异步的方式来完成。
4.2 ConcurrentHashMap优化特性
并发场景的性能提升
4.3 淘汰算法W-LFU
常规的缓存淘汰算法一般采用FIFO、LRU或者LFU,但是这些算法在实际缓存场景中都会存在一些弊端:
算法 | 弊端说明 |
FIFO | 先进先出策略,属于一种最为简单与原始的策略。如果缓存使用频率较高,会导致缓存数据始终在不停的进进出出,影响性能,且命中率表现也一般。 |
LRU | 最近最久未使用策略,保留最近被访问到的数据,而淘汰最久没有被访问的数据。如果遇到偶尔的批量刷数据情况,很容易将其他缓存内容都挤出内存,带来缓存击穿的风险。 |
LFU | 最近少频率策略,这种根据访问次数进行淘汰,相比而言内存中存储的热点数据命中率会更高些,缺点就是需要维护独立字段用来记录每个元素的访问次数,占用内存空间。 |
为了保证命中率,一般缓存框架都会选择使用LRU或者LFU策略,很少会有使用FIFO策略进行数据淘汰的。Caffeine缓存的LFU采用了Count-Min Sketch频率统计算法,由于该LFU的计数器只有4bit大小,所以称为TinyLFU。在TinyLFU算法基础上引入一个基于LRU的Window Cache,这个新的算法叫就叫做W-TinyLFU。
W-TinyLFU算法有效的解决了LRU以及LFU存在的弊端,为Caffeine提供了大部分场景下近乎完美的命中率表现。
4.4 Caffeine使用
引入依赖
<dependency> <groupId>com.github.ben-manes.caffeine</groupId> <artifactId>caffeine</artifactId> </dependency>
容器创建
和Guava Cache创建缓存对象的操作相似,我们可以通过构造器来方便的创建出一个Caffeine对象。
Cache<Integer, String> cache = Caffeine.newBuilder().build();
除了上述这种方式,Caffeine还支持使用不同的构造器方法,构建不同类型的Caffeine对象。对各种构造器方法梳理如下:
方法 | 含义说明 |
build() | 构建一个手动回源的Cache对象 |
build(CacheLoader) | 构建一个支持使用给定CacheLoader对象进行自动回源操作的LoadingCache对象 |
buildAsync() | 构建一个支持异步操作的异步缓存对象 |
buildAsync(CacheLoader) | 使用给定的CacheLoader对象构建一个支持异步操作的缓存对象 |
buildAsync(AsyncCacheLoader) | 与buildAsync(CacheLoader)相似,区别点仅在于传入的参数类型不一样。 |
手动回源,自动回源
public static AsyncCache<String, User> asyncCache() { AsyncCache<String, User> asyncCache = Caffeine.newBuilder() .buildAsync(); asyncCache.get("123", CaffeineDemo::findUserFromDb).join(); return asyncCache; } public static AsyncLoadingCache<String, User> asyncLoadingCache() { return Caffeine.newBuilder() .initialCapacity(1000) // 指定初始容量 .maximumSize(10000L) // 指定最大容量 .expireAfterWrite(30L, TimeUnit.MINUTES) // 指定写入30分钟后过期 .refreshAfterWrite(1L, TimeUnit.MINUTES) // 指定每隔1分钟刷新下数据内容 .removalListener((key, value, cause) -> System.out.println(key + "remove: " + cause)) // 监听记录移除事件 .recordStats() // 开启缓存操作数据统计 .buildAsync(CaffeineDemo::findUserFromDb); } User user = asyncLoadingCache.get("123").join();
在创建缓存对象的同时,可以指定此缓存对象的一些处理策略,比如容量限制、比如过期策略等等。
方法 | 含义说明 |
initialCapacity | 待创建的缓存容器的初始容量大小(记录条数) |
maximumSize | 指定此缓存容器的最大容量(最大缓存记录条数) |
maximumWeight | 指定此缓存容器的最大容量(最大比重值),需结合weighter方可体现出效果 |
expireAfterWrite | 设定过期策略,按照数据写入时间进行计算 |
expireAfterAccess | 设定过期策略,按照数据最后访问时间来计算 |
expireAfter | 基于个性化定制的逻辑来实现过期处理(可以定制基于新增、读取、更新等场景的过期策略,甚至支持为不同记录指定不同过期时间) |
weighter | 入参为一个函数式接口,用于指定每条存入的缓存数据的权重占比情况。这个需要与maximumWeight结合使用 |
refreshAfterWrite | 缓存写入到缓存之后 |
recordStats | 设定开启此容器的数据加载与缓存命中情况统计 |
业务使用
方法 | 含义说明 |
get | 根据key获取指定的缓存值,如果没有则执行回源操作获取 |
getAll | 根据给定的key列表批量获取对应的缓存值,返回一个map格式的结果,没有命中缓存的部分会执行回源操作获取 |
getIfPresent | 不执行回源操作,直接从缓存中尝试获取key对应的缓存值 |
getAllPresent | 不执行回源操作,直接从缓存中尝试获取给定的key列表对应的值,返回查询到的map格式结果, 异步场景不支持此方法 |
put | 向缓存中写入指定的key与value记录 |
putAll | 批量向缓存中写入指定的key-value记录集,异步场景不支持此方法 |
asMap | 将缓存中的数据转换为map格式返回 |
5 Spring Cache注解
(1)@CacheConfig:主要用于配置该类中会用到的一些共用的缓存配置
(2)@Cacheable:主要方法返回值加入缓存。同时在查询时,会先从缓存中取,若不存在才再发起对数据库的访问。
(3)@CachePut:配置于函数上,能够根据参数定义条件进行缓存,与@Cacheable不同的是,每次回真实调用函数,所以主要用于数据新增和修改操作上。
(4)@CacheEvict:配置于函数上,通常用在删除方法上,用来从缓存中移除对应数据
(5)@Caching:配置于函数上,组合多个Cache注解使用。

