type
Post
status
Published
date
Feb 19, 2024
slug
summary
tags
开发
思考
category
技术分享
icon
password
1.场景分析2.如何对加密后的数据进行模糊查询2.1 先解密再查询2.2 明文映射表2.3 数据库层面进行解密查询2.4 分词密文映射表3.其他方案淘宝密文字段检索方案:阿里巴巴文字段检索方案:拼多多密文字段检索方案:京东密文字段检索方案:其他(算法层面)参考
1.场景分析
假如有类似这样的一个场景:有一个人员管理的功能,人员信息列表的主要字段有姓名、性别、用户账号、手机号码、身份证号码、家庭住址、注册日期等,可以对任意一条数据进行增、删、改、查,其中姓名、身份证号码、手机号码字段要支持模糊查询。
区别:比如说密码我们需要加密存储,一般使用的都是不可逆的慢hash算法,慢hash算法可以避免暴力破解(典型的用时间换安全性),在检索时我们既不需要解密也不需要模糊查找,直接使用密文完全匹配。但是手机号就不能这样做,因为手机号我们要查看原信息,并且对手机号还需要支持模糊查找。
手机号码、身份证号码、家庭住址字段数据是敏感数据,这些字段的数据是要加密存储在数据库里,在页面上展示的时候需要进行脱敏处理的。
如果用户想要查询真实姓名是包含有“张三”的所有人员信息,可以在页面上输入一个关键字,如“张三”,点击开始查询后,这个参数会传递到后台,后台会执行一条sql,如“
select * from person where name like '%张三%'”,执行结果中包含了所有用户真实姓名包含有“张三”的所有数据记录,如“张三”,“张三丰”等。如果用户要查询手机号码尾号是“0537”的用户,后台执行类似与姓名模糊查询的sql,"
select * from person where phone like '%0537'",肯定是得不到正确的结果的,因为手机号码字段在数据库中的数据是加密后的结果,而‘0537’是明文。身份证号码、家庭住址等其他敏感字段在模糊查询的时候也都有类似这样的问题,这也是敏感字段模糊查询的痛点,即模糊查询关键字与实际存储的数据不一致。2.如何对加密后的数据进行模糊查询
2.1 先解密再查询
查询出目标表内所有的数据,在内存中(服务端解密)对要模糊查询的敏感字段的加密数据进行解密,然后再遍历解密后的数据,与模糊查询关键字进行比较,筛选出包含有模糊查询关键字的数据行。
这种方法是最容易想到的,但有一个比较明显的问题是,模糊查询的过程是在内存中进行的,如果数据量特别大,很容易导致内存溢出,因此不推荐在生产中使用这种方法
例如:一个英文字母(不分大小写)占一个字节的空间,一个中文汉字占两个字节的空间,用DES来举例,13800138000加密后的串HE9T75xNx6c5yLmS5l4r6Q==占24个字节。
条数 | Bytes | MB |
100w | 2400万 | 22.89 |
1000w | 2.4亿 | 228.89 |
1亿 | 24亿 | 2288.89 |
2.2 明文映射表
新建一张映射表,存储敏感字段解密后的数据与目标表主键的映射表,需要模糊查询的时候,先对明文映射表进行模糊查询,得到符合条件的目标数据的主键,再返回来根据主键查询目标表。
这种方法,实际上是有点掩耳盗铃的感觉,敏感字段加密存储的字段主要是考虑到安全性,使用明文映射表来存储解密后的敏感字段,实际上相当于敏感字段没有加密存储,与最被要对敏感字段加密的初衷相违背,因此不推荐在生产中使用这种方法。
2.3 数据库层面进行解密查询
后台在执行查询sql时对敏感字段先解密,然后再执行like,以上面的人员管理列表模糊查询为例,即对sql的改造为:“
select * from person where AES_DECRYPT(phone,'key') like '%0537'”。这种方法的优点是,成本比较小,容易实现,但是缺点很明显,该字段无法通过数据库索引来优化查询,另外有一些数据库无法保证数据库的加解密算法与程序的加解密算法一致,可能会导致可以程序中加密,但是无法在数据库中解密的或者可以在数据库加密无法在程序中解密的问题,因此不推荐在生产中使用这种方法。
如果对查询性能要求不是特别高、对数据安全性要求一般,可以使用常见的加解密算法比如说AES、DES之类的也是一个不错的选择。
2.4 分词密文映射表
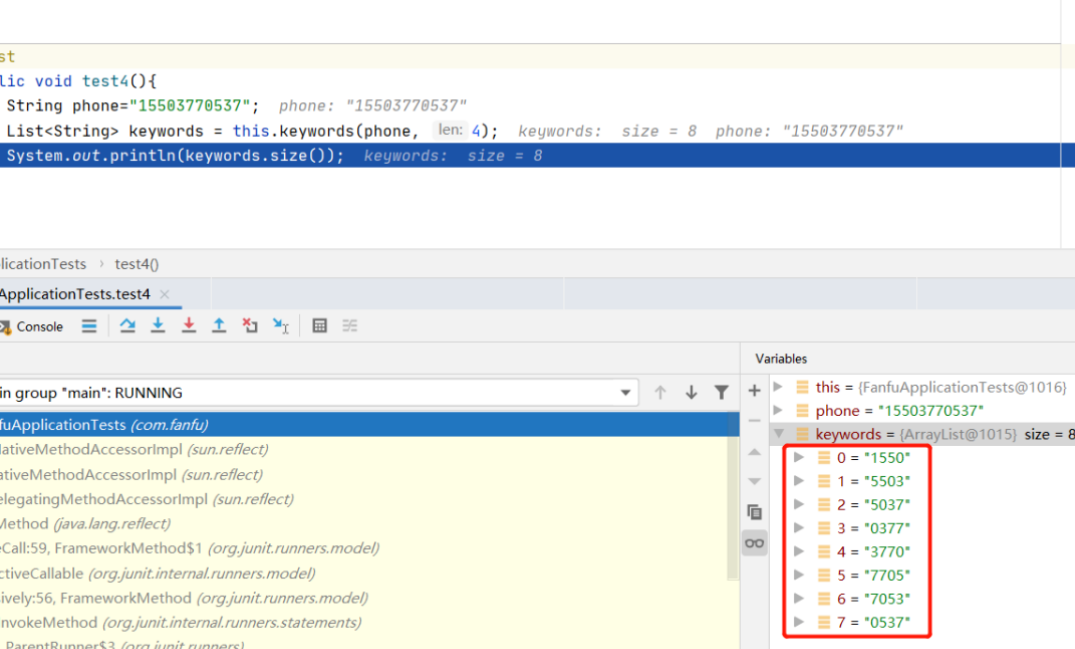
这种方法是对第二种思路的基础上进行延伸优化,也是主流的方法。新建一张分词密文映射表,在敏感字段数据新增、修改后,对敏感字段进行分词组合,如“13800138000”的分词组合有“138”、“0013”、“8000”等,再对每个分词进行加密,建立起敏感字段的分词密文与目标数据行主键的关联关系;在处理模糊查询的时候,对模糊查询关键字进行加密,用加密后的模糊查询关键字,对分词密文映射表进行like查询,得到目标数据行的主键,再以目标数据行的主键为条件返回目标表进行精确查询。
这种方法的优点就是原理简单,实现起来也不复杂,但是有一定的局限性,算是一个对性能、业务相折中的一个方案,相比较之下,在能想的方法中,比较推荐这种方法,但是要特别注意的是,对模糊查询的关键字的长度,要在业务层面进行限制;以手机号为例,可以要求对模糊查询的关键字是四位或者是五位,具体可以再根据具体的场景进行详细划分。
为什么要增加这样的限制呢?因为明文加密后长度为变长,有额外的存储成本和查询性能成本,分词组合越多,需要的存储空间以及所消耗的查询性能成本也就更大,并且分词越短,被硬破解的可能性也就越大,也会在一定程度上导致安全性降低。我们都知道加密后长度会增长,增长的这部分长度存储就是我们要花费的额外成本,典型的使用成本来换取速度,密文增长的幅度随着算法不同而不同以DES举例,13800138000加密前占11个字节,加密后的串HE9T75xNx6c5yLmS5l4r6Q==占24个字节,增长是2.18倍。
代码
package love.javaer.encrypt.demo; import cn.hutool.crypto.SecureUtil; import cn.hutool.crypto.symmetric.SymmetricAlgorithm; import cn.hutool.crypto.symmetric.SymmetricCrypto; import java.util.HashMap; import java.util.Map; /** * Hello world! * */ public class App { private static final String SECRET = "guaziguazi"; private static final Integer SPLIT_SIZE = 4; private static final Map<String, String> MAP = new HashMap<>(); static { MAP.put("15870090015", "Bh76FLu9h20=~js42iJPdg1A=~QyaE9gWK+Os=~3sWjlbJvQCQ=~YZaDebncAbA=~J/IMRcXa8ps=~d9KN686EAog=~dzLqG/kfvUU=~"); MAP.put("15870090016", "Bh76FLu9h20=~js42iJPdg1A=~QyaE9gWK+Os=~3sWjlbJvQCQ=~YZaDebncAbA=~J/IMRcXa8ps=~d9KN686EAog=~ZN88RzoHaPw=~"); MAP.put("15970090015", "uzw5wFjj21k=~IS4Yma89QhI=~T6g55VLvYw8=~3sWjlbJvQCQ=~YZaDebncAbA=~J/IMRcXa8ps=~d9KN686EAog=~dzLqG/kfvUU=~"); } public static void main(String[] args) { String phoneKeywords = phoneKeywords("15870090015"); System.out.println("phoneKeywords is: " + phoneKeywords); MAP.forEach((k, v) -> { if (v.endsWith(encrypt("0015") + "~")) { System.out.println("endsWith key is: " + k); } }); MAP.forEach((k, v) -> { if (v.startsWith(encrypt("1587"))) { System.out.println("startsWith key is: " + k); } }); } private static String phoneKeywords(String phone) { String keywords = keywords(phone, SPLIT_SIZE); System.out.println(keywords.length()); return keywords; } private static String keywords(String word, int len) { StringBuilder sb = new StringBuilder(); for (int i = 0; i < word.length(); i++) { int end = i + len; String sub1 = word.substring(i, end); sb.append(encrypt(sub1)); sb.append("~"); if (end == word.length()) { break; } } return sb.toString(); } public static String decrypt(String val) { byte[] key = SecureUtil.generateKey(SymmetricAlgorithm.DES.getValue(), SECRET.getBytes()).getEncoded(); SymmetricCrypto des = new SymmetricCrypto(SymmetricAlgorithm.DES, key); return des.decryptStr(val); } public static String encrypt(String val) { byte[] key = SecureUtil.generateKey(SymmetricAlgorithm.DES.getValue(), SECRET.getBytes()).getEncoded(); SymmetricCrypto des = new SymmetricCrypto(SymmetricAlgorithm.DES, key); return des.encryptBase64(val); } }
3.其他方案
淘宝密文字段检索方案:
阿里巴巴文字段检索方案:
密文检索的功能实现是根据4位英文字符(半角),2个中文字符(全角)为一个检索条件。将一个字段拆分为多个,
比如:taobao123
使用4个字符为一组的加密方式。
第一组taob,第二组aoba,第三组obao,第四组bao1… 依次类推
如果需要检索所有包含检索条件4个字符的数据比如:aoba,加密字符后通过key like “%partial%”查库。
因为密文检索开启后密文长度会膨胀几倍以上,如果没有强需求建议不开启。
但是使用这种方式也有一定代价:
- 支持模糊查询加密方式,产出的密文比较长;
- 支持的模糊查询子句长度必须大于等于4个英文/数字,或者2个汉字。不支持过短的查询(出于安全考虑);
- 返回的结果列表中有可能有多余的结果,需要增加筛选的逻辑:对记录先解密,再筛选;
…
拼多多密文字段检索方案:
完整加密串和检索串要分离,可从完整字符串中提取检索串。
完整加密串和检索串分别存储数据表两个字段。因为加密后的数据长度会扩大 10-20 倍,应该减少索引字段的长度,提高检索效率低。加密原串用于开展业务,检索串用于数据查询使用。
京东密文字段检索方案:
这些方法优点就是实现起来不算复杂,使用起来也较为简单,算是一个折中的做法,因为会有扩展字段存储成本会有升高,但是可利用数据库索引优化查询速度,推荐使用这个方法。